|
|

机器学习生命周期机器学习使计算机系统能够在没有明确编程的情况下自动学习。但是机器学习系统是如何工作的呢?所以,它可以用机器学习的生命周期来描述。机器学习生命周期是构建高效机器学习项目的循环过程。生命周期的主要目的是找到问题或项目的解决方案。 机器学习生命周期包括七个主要步骤,具体步骤如下:
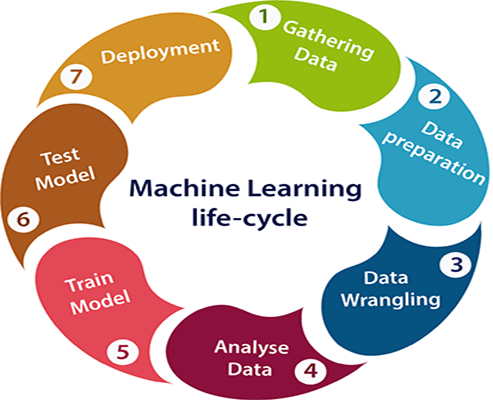 在整个过程中最重要的事情是理解问题和知道问题的目的。因此,在开始生命周期之前,我们需要了解问题,因为好的结果取决于对问题的更好理解。 在完整的生命周期过程中,为了解决一个问题,我们创建了一个叫做“模型”的机器学习系统,这个模型是通过提供“训练”来创建的。但是要训练一个模型,我们需要数据,因此,生命周期从收集数据开始。 1.收集数据:数据收集是机器学习生命周期的第一步。此步骤的目标是识别和获取所有与数据相关的问题。 在这一步中,我们需要确定不同的数据源,因为数据可以从各种来源收集,例如文件,数据库,互联网,或移动设备.这是生命周期中最重要的步骤之一。收集数据的数量和质量将决定输出的效率。数据越多,预测就越准确。 该步骤包括以下任务:
通过执行上述任务,我们得到一组连贯的数据,也称为数据集.它将在进一步的步骤中使用。 2.数据准备收集数据后,我们需要为进一步的步骤做准备。数据准备是一个步骤,我们将数据放在合适的地方,并准备在我们的机器学习训练中使用。 在这一步中,首先,我们将所有数据放在一起,然后随机化数据的顺序。 这一步可以进一步分为两个过程:
3.数据争吵数据整理是将原始数据清理并转换为可用格式的过程。它是清理数据、选择要使用的变量并以适当的格式转换数据以使其更适合于下一步的分析的过程。这是整个过程中最重要的步骤之一。为了解决质量问题,需要清理数据。 我们收集的资料未必总是有用,因为有些资料未必有用。在实际应用中,收集的数据可能存在各种问题,包括:
因此,我们使用各种过滤技术来清理数据。 检测和消除上述问题是强制性的,因为它会对结果的质量产生负面影响。 4.数据分析现在,已清理和准备好的数据被传递到分析步骤。这一步包括:
这一步的目的是建立一个机器学习模型,使用各种分析技术分析数据并审查结果。它从确定问题的类型开始,在这里我们选择机器学习技术,例如分类,回归,聚类分析,协会等,然后利用准备好的数据建立模型,并对模型进行评估。 因此,在这一步中,我们获取数据并使用机器学习算法来构建模型。 5.火车模型现在,下一步是训练模型,在这一步中,我们训练我们的模型来提高它的性能,以获得更好的问题结果。 我们使用各种机器学习算法使用数据集来训练模型。训练一个模型是必须的,这样它才能理解各种模式、规则和特征。 6.测试模型一旦我们的机器学习模型在给定的数据集上进行了训练,然后我们测试模型。在这一步中,我们通过提供一个测试数据集来检查模型的准确性。 对模型的测试决定了模型根据项目或问题的要求的准确率百分比。 7.部署机器学习生命周期的最后一步是部署,我们将模型部署到现实系统中。 如果上面准备的模型能够以可接受的速度产生符合我们要求的准确结果,那么我们就可以将模型部署到实际系统中。但是在部署项目之前,我们将检查它是否使用可用数据提高了性能。部署阶段类似于为项目制作最终报告。
下一个话题
安装Anaconda和Python
|
 观看视频请加入我们的Youtube频道:现在加入
观看视频请加入我们的Youtube频道:现在加入
反馈
- 将你的反馈发送至(电子邮件保护)
帮助他人,请分享








