|
|

数据科学初学者教程数据科学已经成为21世纪要求最高的工作。每个组织都在寻找具有数据科学知识的候选人。在本教程中,我们将介绍数据科学,包括数据科学的工作角色、数据科学的工具、数据科学的组件、应用程序等。 我们开始吧, 
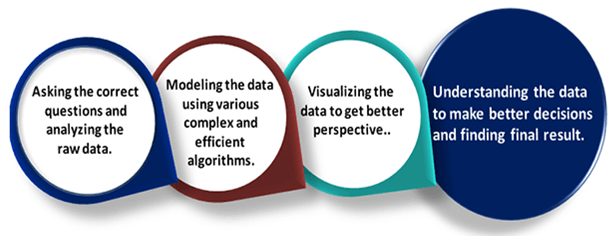
什么是数据科学?数据科学是对大量数据的深入研究,包括从使用科学方法、不同技术和算法处理的原始、结构化和非结构化数据中提取有意义的见解。 它是一个多学科领域,使用工具和技术来操作数据,以便您可以找到新的和有意义的东西。 数据科学使用最强大的硬件、编程系统和最有效的算法来解决与数据相关的问题。这是人工智能的未来。 简而言之,我们可以说数据科学是关于:
 例子:假设我们要乘汽车从A站到B站。现在,我们需要做出一些决定,比如哪条路线是最快到达目的地的最佳路线,哪条路线不会堵车,哪条路线性价比高。所有这些决策因素都将作为输入数据,我们将从这些决策中得到一个合适的答案,所以这种对数据的分析称为数据分析,这是数据科学的一部分。 对数据科学的需求: 几年前,数据很少,大部分以结构化形式提供,可以轻松地存储在excel表格中,并使用BI工具进行处理。 但在当今世界,数据变得如此庞大,即大约2.5英制字节每天都有大量的数据产生,这导致了数据爆炸。据研究估计,到2020年,地球上的一个人每秒钟将产生1.7 MB的数据。每个公司都需要数据来工作、发展和改进他们的业务。 现在,处理如此大量的数据对每个组织来说都是一项具有挑战性的任务。因此,为了处理、处理和分析这些数据,我们需要一些复杂、强大、高效的算法和技术,这些技术就是数据科学。以下是使用数据科学技术的一些主要原因:
数据科学岗位:根据各种调查,由于对数据科学的需求不断增加,数据科学家的工作正在成为21世纪要求最高的工作。有些人也称之为“the21世纪最热门的工作头衔”。数据科学家是能够使用各种统计工具和机器学习算法来理解和分析数据的专家。 数据科学家的平均工资范围约为每年9.5万至16.5万美元,根据不同的研究,大约11.5数百万今年将创造出大量的就业机会2026. 数据科学工作类型如果你学习数据科学,那么你就有机会在这个领域找到各种令人兴奋的工作角色。主要工作职责如下:
下面是一些数据科学的关键职位的解释。 1.数据分析: 数据分析师是一个人,他们对大量数据进行挖掘,对数据建模,寻找模式、关系、趋势等。在一天结束时,他提出了可视化和报告,用于分析决策和解决问题的过程中的数据。 技能要求:要成为一名数据分析师,您必须具备良好的数据分析背景数学,商业智能,数据挖掘的基本知识统计数据.你还应该熟悉一些计算机语言和工具,如MATLAB, Python, SQL, Hive, Pig, Excel, SAS, R, JS, Spark等。 2.机器学习专家: 机器学习专家是处理数据科学中使用的各种机器学习算法的人,例如回归,聚类,分类,决策树,随机森林等。 技能要求:计算机编程语言,如Python, c++, R, Java和Hadoop。你还应该了解各种算法,解决问题的分析能力,概率和统计学。 3.数据工程师: 数据工程师处理大量数据,负责构建和维护数据科学项目的数据架构。数据工程师还负责创建用于建模、挖掘、采集和验证的数据集过程。 技能要求:数据工程师必须有深度的知识SQL, MongoDB, Cassandra, HBase, Apache Spark, Hive, MapReduce具有一定的语言知识Python, C/ c++, Java, Perl等。 4.数据科学家: 数据科学家是一种专业人士,他们通过部署各种工具、技术、方法、算法等,处理大量数据,得出令人信服的业务见解。 技能要求:要成为一名数据科学家,一个人应该具备技术语言技能,例如R、SAS、SQL、Python、Hive、Pig、Apache spark、MATLAB.数据科学家必须了解统计学、数学、可视化和沟通技巧。 数据科学前提非技术先决条件:
技术的先决条件:
BI和数据科学的区别BI代表商业智能,也用于商业信息的数据分析:以下是BI和数据科学之间的一些区别:
数据科学组成部分: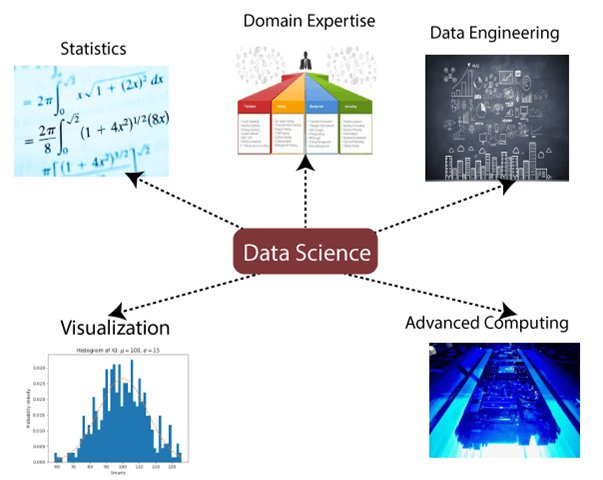 数据科学的主要组成部分如下: 1.统计:统计学是数据科学中最重要的组成部分之一。统计学是收集和分析大量的数字数据,并从中发现有意义的见解的一种方法。 2.专业领域:在数据科学中,领域专业知识将数据科学绑定在一起。领域专长是指某一特定领域的专业知识或技能。在数据科学中,我们需要各个领域的专家。 3.数据工程:数据工程是数据科学的一部分,涉及数据的获取、存储、检索和转换。数据工程还包括数据的元数据(关于数据的数据)。 4.可视化:数据可视化是指将数据表示在可视化的上下文中,以便人们容易理解数据的意义。数据可视化可以很容易地以可视化的方式访问大量数据。 5.先进的计算:数据科学的重头戏是高级计算。高级计算包括设计、编写、调试和维护计算机程序的源代码。 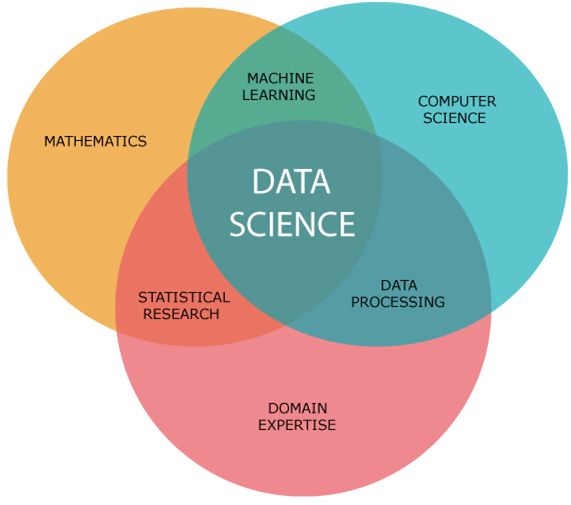 6.数学:数学是数据科学的关键部分。数学涉及对数量、结构、空间和变化的研究。对于数据科学家来说,良好的数学知识是必不可少的。 7.机器学习:机器学习是数据科学的支柱。机器学习就是为机器提供训练,使其可以充当人类的大脑。在数据科学中,我们使用各种机器学习算法来解决问题。 数据科学工具以下是数据科学所需的一些工具:
数据科学中的机器学习要成为一名数据科学家,还应该了解机器学习及其算法,因为在数据科学中,有各种广泛使用的机器学习算法。以下是一些用于数据科学的机器学习算法的名称:
我们将在这里简要介绍一些重要的算法, 1.线性回归算法:线性回归是最流行的基于监督学习的机器学习算法。该算法的工作原理是回归,这是一种基于自变量的目标值建模方法。它表示线性方程的形式,它在输入集和预测输出之间有关系。该算法主要用于预测和预测。由于它表现的是输入变量和输出变量之间的线性关系,因此称为线性回归。 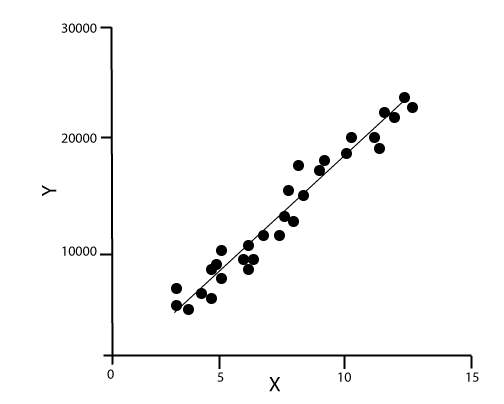 下式可以描述x和y变量之间的关系: 在那里,y因变量 2.决策树:决策树算法是另一种机器学习算法,属于监督学习算法。这是最流行的机器学习算法之一。它可以用于分类和回归问题。 在决策树算法中,我们可以通过使用树表示法来解决这个问题,其中每个节点代表一个特征,每个分支代表一个决策,每个叶子代表结果。 下面是一个Job offer问题的例子: 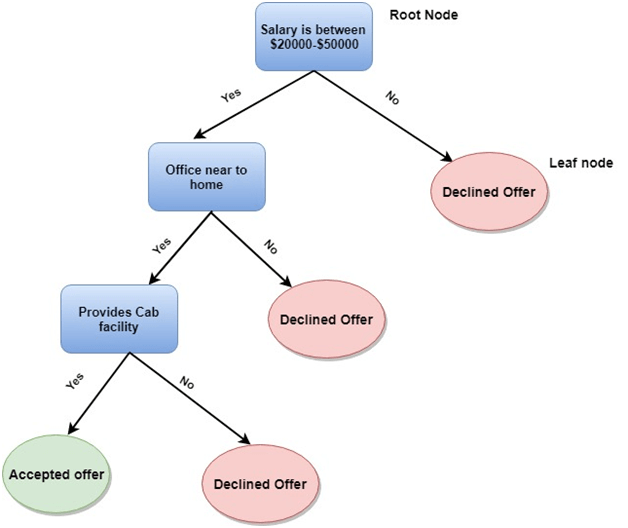 在决策树中,我们从树的根开始,比较根属性和记录属性的值。在此比较的基础上,我们根据值跟踪分支,然后移动到下一个节点。我们继续比较这些值,直到到达具有预测类值的叶节点。 3.k - means聚类:k均值聚类是机器学习中最流行的算法之一,属于无监督学习算法。它解决了集群问题。 如果给我们一个项目的数据集,具有一定的特征和值,我们需要将这些项目分组,所以这类问题可以用k-means聚类算法来解决。 K-means聚类算法的目标是最小化一个目标函数,即平方误差函数,表示为: 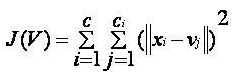 在哪里, J(V) =>目标函数 如何使用机器学习算法解决数据科学中的问题?现在,让我们了解在数据科学中发生的最常见的问题类型以及解决这些问题的方法是什么。因此,在数据科学中,问题是通过算法来解决的,下面是可能问题的适用算法的图表表示: 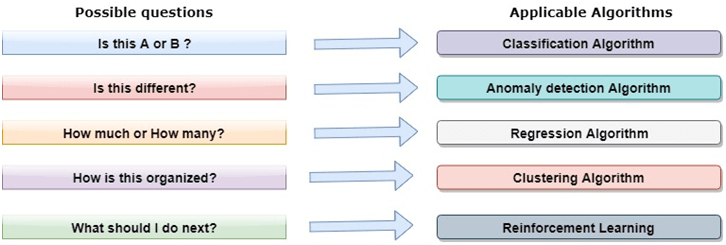 这是A还是B?: 我们可以参考这类只有两个固定答案的问题,如是或否,1或0,可能或不可能。这类问题可以用分类算法来解决。 这有什么不同吗?: 我们可以参考这类问题,它属于各种各样的模式,我们需要从中找到奇数。这类问题可以使用异常检测算法来解决。 How much or How many? 另一种类型的问题是需要数值或数字,比如今天的时间是多少,今天的温度是多少,可以使用回归算法来解决。 这是如何组织的? 现在,如果你有一个需要处理数据组织的问题,那么它可以使用聚类算法来解决。 聚类算法根据特征、颜色或其他共同特征对数据进行组织和分组。 数据科学生命周期数据科学的生命周期如下图所示。 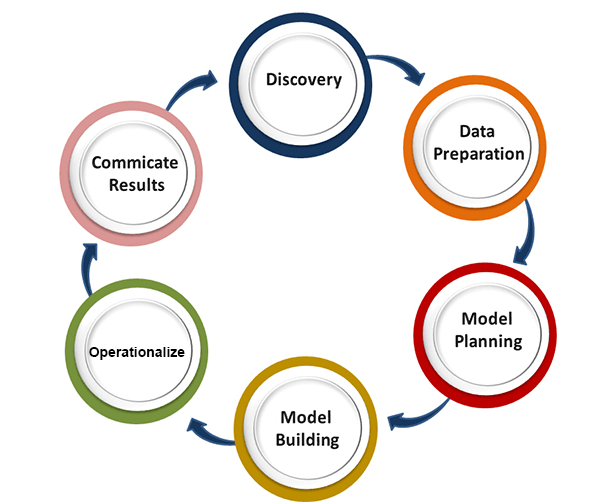 数据科学生命周期的主要阶段如下: 1.发现:第一个阶段是发现,包括提出正确的问题。当您开始任何数据科学项目时,您需要确定基本需求、优先级和项目预算。在这个阶段,我们需要确定项目的所有需求,例如人员数量、技术、时间、数据和最终目标,然后我们可以在第一个假设层面上构建业务问题。 2.数据准备:数据准备也被称为数据调整。在这一阶段,我们需要完成以下任务:
在执行上述所有任务之后,我们可以很容易地将这些数据用于我们的进一步处理。 3.模型规划:在这个阶段,我们需要确定建立输入变量之间关系的各种方法和技术。我们将应用探索性数据分析(EDA),使用各种统计公式和可视化工具来理解变量之间的关系,并查看数据可以告诉我们什么。用于模型规划的常用工具有:
4.模型:在此阶段,开始构建模型的过程。我们将创建用于训练和测试的数据集。我们将应用不同的技术,如关联、分类和聚类,来构建模型。 以下是一些常用的模型构建工具:
5.实施:在此阶段,我们将交付项目的最终报告,以及简报、代码和技术文档。在完全部署之前,此阶段为您提供完整项目性能和其他组件的小规模清晰概述。 6.沟通结果:在这个阶段,我们将检查我们是否达到了我们在初始阶段设定的目标。我们将与业务团队沟通调查结果和最终结果。 数据科学的应用:
下一个话题
数据网格——重新思考企业数据架构
|
 观看视频请加入我们的Youtube频道:现在加入
观看视频请加入我们的Youtube频道:现在加入
反馈
- 将你的反馈发送至(电子邮件保护)
帮助他人,请分享








