|
|

k - means聚类算法k - means聚类是一种无监督学习算法,用于解决机器学习或数据的聚类问题的科学。在这个主题中,我们将学习什么是k - means聚类算法,算法是如何工作的,以及k - means聚类的Python实现。 k - means算法是什么?k - means聚类是一个无监督学习算法,这组无标号数据集到不同的集群。这里K定义预定义的集群的数量需要创建在这个过程中,如果K = 2,会有两个集群,K = 3,将有三个集群,等等。 它是一种迭代算法,将无标号数据集划分为k不同集群以这样一种方式,每个数据集是只有一组相似的属性。 它允许我们集群的数据分成不同的组和一个方便的方式发现组织的类别标记数据集本身不需要任何训练。 centroid-based算法,在每个集群与重心。该算法的主要目的是减少数据点之间的距离的总和及其相应的集群。 算法以无标号数据集作为输入,将数据集划分为k-number集群,重复这个过程,直到没有找到最好的集群。k的值应该是预先确定的算法。 的k - means聚类算法主要完成两个任务:
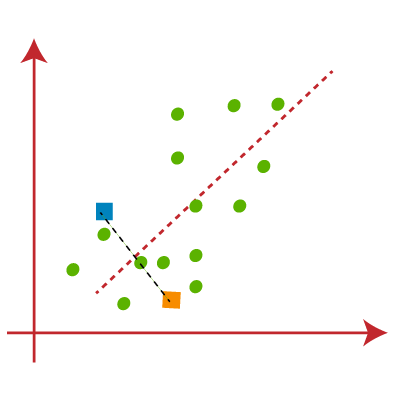
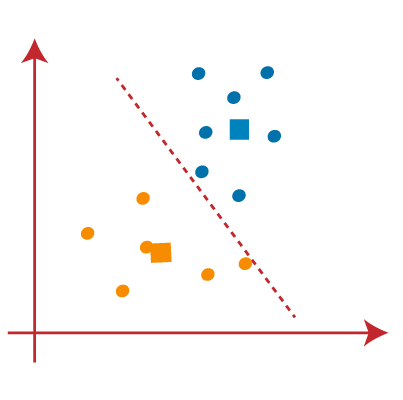
因此每个集群点了一些共性,远离其他集群。 以下图解释了k - means聚类算法的工作: 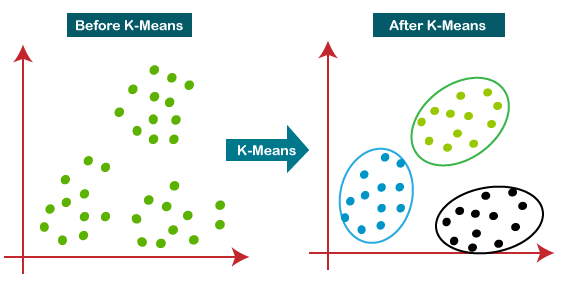 k - means算法是如何工作的呢?k - means算法的工作解释以下步骤: 步骤1:选择数K决定簇的数量。 步骤2:选择随机K点或质心。(它可以其他从输入数据集)。 步骤3:将每个数据点分配给他们最亲密的重心,将形成预定义的K集群。 步骤4:计算方差和每个集群的新的重心。 步骤5:重复第三步骤,这意味着重新分配每个数据点到每个集群的新最亲密的重心。 步骤6:如果产生任何分配,然后去其他步骤4去完成。 步骤7:模型是准备好了。 让我们通过考虑可视情节理解上面的步骤: 假设我们有两个变量狭义货币供应量M1及广义货币供应量M2。x - y轴这两个变量的散点图如下所示: 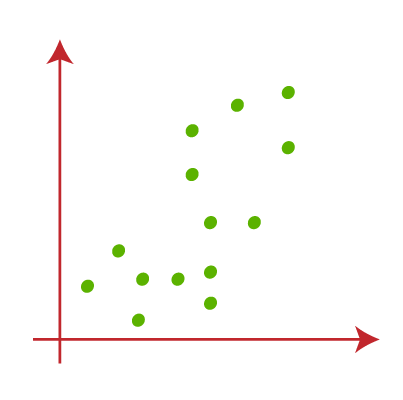
从上面的图片,很明显,点左边的线是K1附近或蓝色的质心,并指向正确的接近黄色的重心。我们的颜色是蓝色和黄色清晰的可视化。 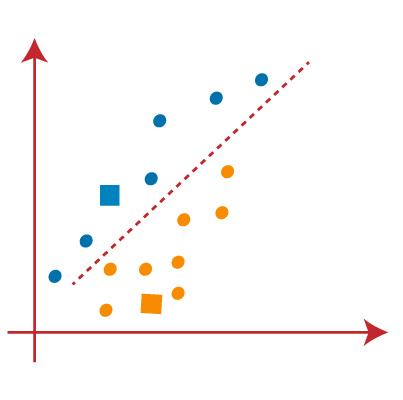
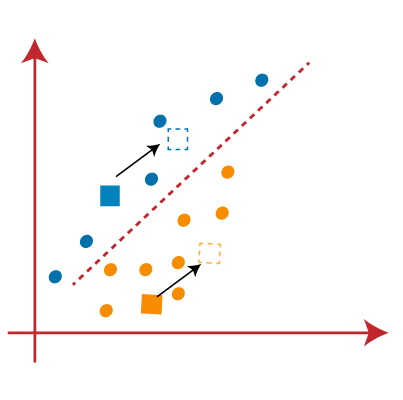
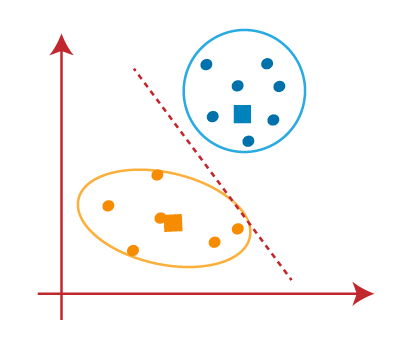
从上图,我们可以看到,一个黄点是线的左侧,和两个蓝色的点是正确的。所以,这些三分将分配给新的重心。 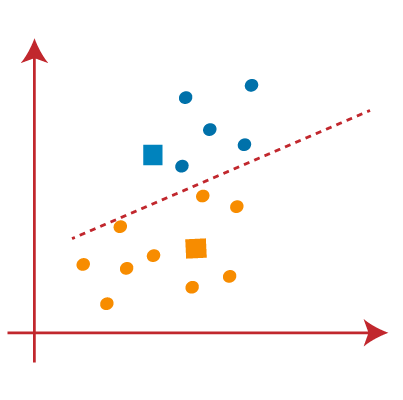 重新分配已经发生,所以我们将再次去第4步,寻找新的重心或K-points。
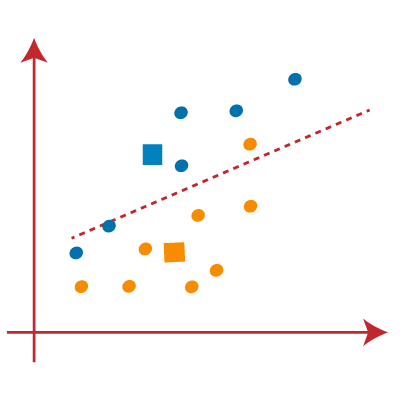
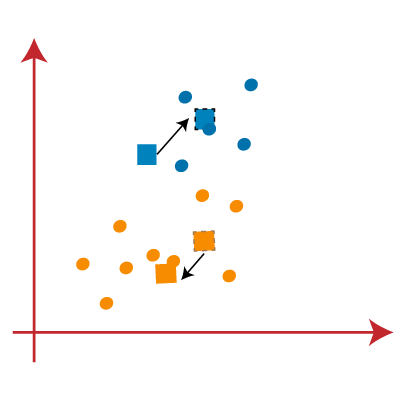
作为我们的模型已经准备好了,我们现在可以把重心,和两个最终集群将如下面图片所示: 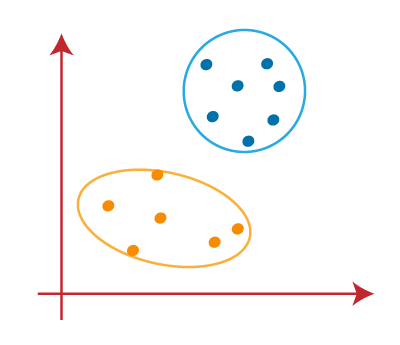 如何选择“K数量的集群”的价值在K - means聚类?k - means聚类算法的性能取决于高效集群形式。但是选择最优数量的集群是一个大的任务。有一些不同的方法找到最优数量的集群,但是我们正在讨论最合适的方法来找到集群的数量或价值的k以下方法: 弯头的方法弯头的方法是最受欢迎的方法之一找到最优数量的集群。这种方法使用wcs价值的概念。wcs代表在集群的平方和总变异,它定义了在一个集群中。wcs的公式计算值(3集群)如下所示:
wcs =∑P我在Cluster1距离(P我C1)2+∑P我在Cluster2距离(P我C2)2+∑P我在CLuster3距离(P我C3)2
wcs的在上面的公式, ∑P我在Cluster1距离(P我C1)2:这是之间的距离的平方的总和每个数据点及其重心在cluster1和其他两项相同。 测量数据和质心之间的距离,我们可以使用任何方法如欧氏距离、曼哈顿距离。 找到最优值的集群,手肘方法遵循以下步骤:
自从图显示了弯管,这看起来像一个弯头,因此它被称为弯头的方法。肘部的图形方法看起来像下面的图片: 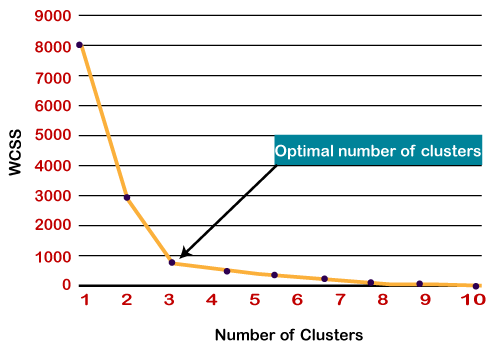 注意:我们可以选择集群的数量等于给定的数据点。如果我们选择集群的数量等于数据点,然后wcs的价值为零,将端点的阴谋。Python k - means聚类算法的实现在上面的小节中,我们已经讨论了k - means算法,现在让我们看看它是如何实现的Python。 在实现之前,让我们了解什么类型的问题我们会解决。所以,我们有一个数据集Mall_Customers,这是客户的数据访问那里的商场,花。 在给定的数据集,我们有Customer_Id,性别、年龄、年收入(美元),和支出的分数的计算值(这是客户在商场花了多少,价值越多,他越花了)。从这个数据集,我们需要计算一些模式,因为它是一个无监督的方法,所以我们不知道计算准确。 实施的步骤之后给出如下:
步骤1:数据预处理步骤第一步将是数据预处理,当我们在早些时候回归和分类的主题。但对于聚类问题,这将是不同于其他模型。让我们讨论一下:
在上面的代码中,numpy我们已经导入执行数学计算,matplotlib绘制图形,熊猫用于管理数据集。
通过执行上面的代码行数,我们将得到数据集的世爵IDE。数据看起来像下面的图片: 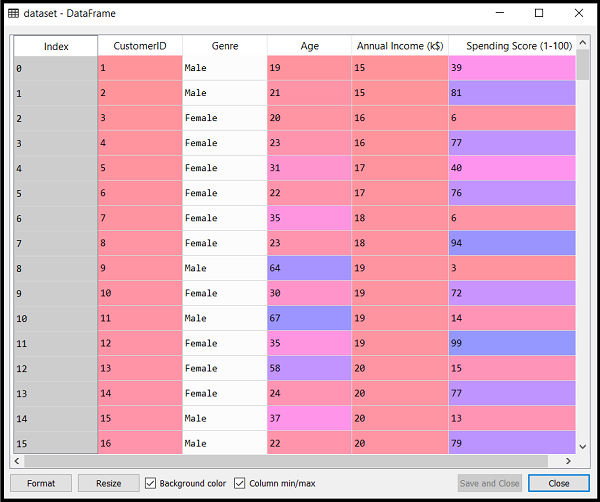 从上面的数据集,我们需要找到一些模式。
在这里,我们不需要任何因变量的数据预处理步骤,因为它是一个聚类问题,我们不知道什么来确定。所以我们只会为矩阵添加一行代码的功能。 正如我们可以看到的,我们只提取3理查德·道金斯和图4th特性。那是因为我们需要一个2 d图来可视化模型,不需要和一些特性,比如customer_id。 第二步:找到最优数量的集群使用弯头的方法在第二步中,我们将试图找到最优数量的集群为我们的聚类问题。所以,正如上面所讨论的,我们会为此使用肘部方法。 正如我们所知,肘部方法使用wcs的概念画的阴谋策划wcs值x轴上的轴和集群的数量。所以我们要计算不同的k值wcs的值从1到10。下面的代码: 我们可以看到在上面的代码中,我们使用的KMeanssklearn类。图书馆集群形成集群。 接下来,我们创建了wcss_list变量初始化一个空列表,用于包含的wcs计算值不同的k值从1到10。 之后,我们已经初始化了for循环迭代的不同的k值从1到10;因为for循环在Python中,排除出站极限,因此作为11包括10th价值。 代码的其余部分是类似我们在早些时候的话题,正如我们所拟合的模型矩阵的特性,然后绘制图形之间的集群和wcs的数量。 输出:执行上面的代码后,我们将得到下面的输出: 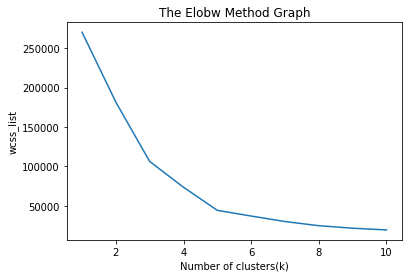 从上面的图中,我们可以看到在肘部点5。这里集群的数量将是5。 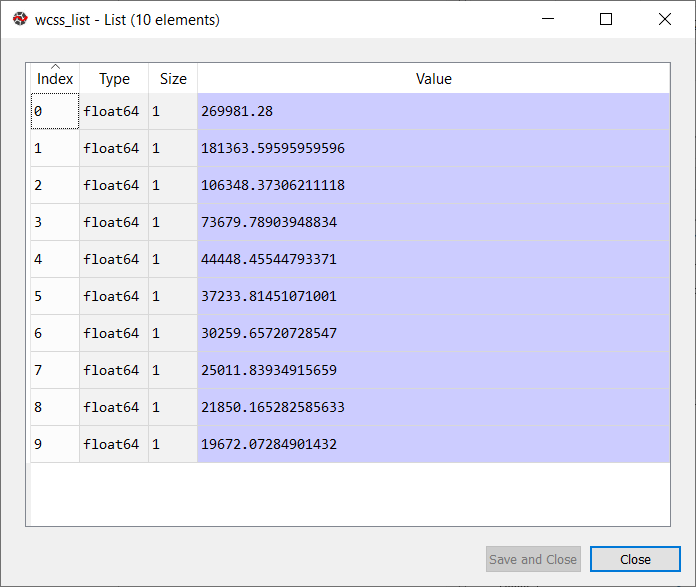 - 3步:培训上的k - means算法训练数据集我们有集群的数量,所以我们现在可以训练数据集上的模型。 训练模型,我们将使用相同的两行代码使用在上面的部分,但是在这里而不是使用我,我们将使用5,我们知道有5个集群形成的需要。下面的代码是: 上面的第一行是一样的,用于创建KMeans类的对象。 在第二行代码中,我们创建了因变量y_predict训练模型。 执行上面的代码行数,我们会y_predict变量。我们可以检查它变量的探险家选择世爵的IDE。我们现在可以比较y_predict的值与原来的数据集。考虑下面的图片: 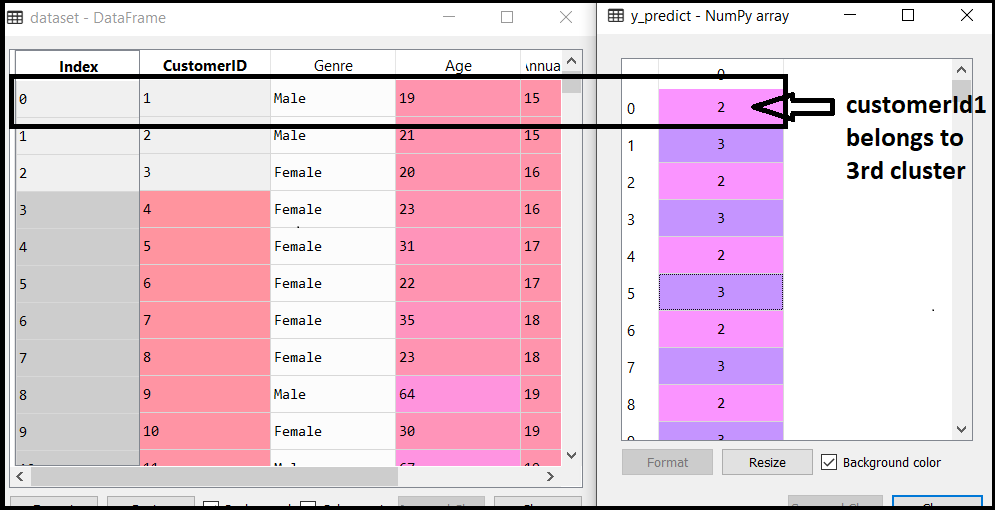 从上面的图片,我们现在可以联系CustomerID 1属于一个集群 3(作为索引从0开始,因此2将被视为3),和2属于集群4,等等。 步骤4:可视化集群最后一步是可视化集群。5集群模型,所以我们会想象每个集群。 集群可视化将使用散点图使用mtp.scatter matplotlib()函数。 在上面的代码中,我们为每个集群所写的代码,从1到5。mtp的第一个坐标。散射,即。x [y_predict = = 0,0]包含x值矩阵的特征值,和y_predict从0到1。 输出: 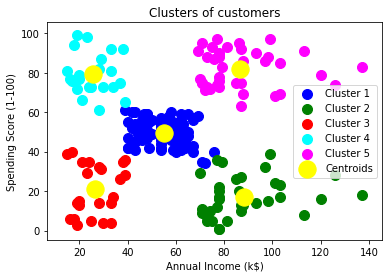 输出图像清晰显示了五个不同的集群不同的颜色。两个参数之间形成的集群的数据集;客户和支出的年度收入。我们可以改变颜色和标签的要求或选择。我们还可以观察到一些点从上面的模式,给出如下:
下一个话题
先验的机器学习算法
|
 加入我们的Youtube频道视频:现在加入
加入我们的Youtube频道视频:现在加入
反馈
- 把你的反馈(电子邮件保护)
帮助别人,请分享








