|
|

机器学习中的逻辑回归
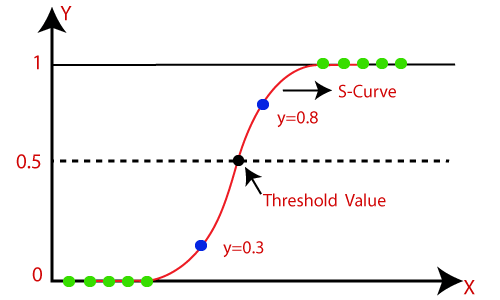 注意:逻辑回归使用预测建模的概念作为回归;因此,它被称为逻辑回归,但用于对样本进行分类;因此,它属于分类算法。Logistic函数(Sigmoid函数):
逻辑回归的假设:
Logistic回归方程:由线性回归方程得到Logistic回归方程。得到Logistic回归方程的数学步骤如下:
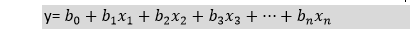
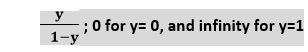
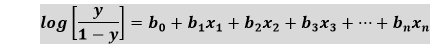 上述方程是逻辑回归的最终方程。 逻辑回归类型:根据分类,逻辑回归可以分为三种类型:
逻辑回归的Python实现(二项)为了理解逻辑回归在Python中的实现,我们将使用下面的例子: 例子:有一个给定的数据集,其中包含从社交网站获得的各种用户的信息。有一家汽车制造公司最近推出了一款新的SUV汽车。所以公司想要检查数据集中有多少用户,想要购买这辆车。 对于这个问题,我们将使用逻辑回归算法建立一个机器学习模型。数据集如下图所示。在这个问题中,我们将预测购买变量(因变量)通过使用年龄和工资(自变量). 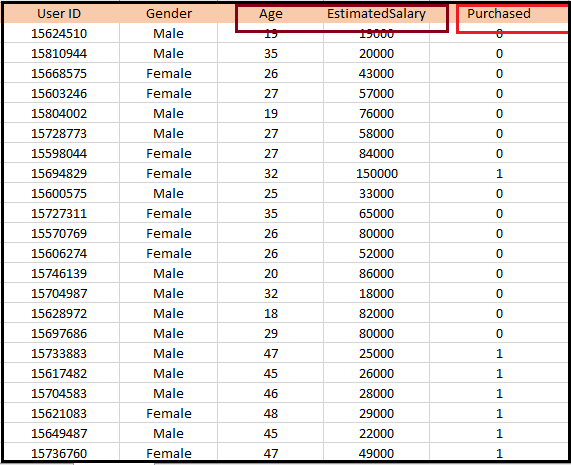 逻辑回归的步骤:为了使用Python实现逻辑回归,我们将使用与之前回归主题相同的步骤。步骤如下:
1.数据预处理步骤:在这一步中,我们将预处理/准备数据,以便我们可以在代码中有效地使用它。这将与我们在数据预处理主题中所做的相同。代码如下所示: 通过执行上面的代码行,我们将得到数据集作为输出。考虑给定的图像: 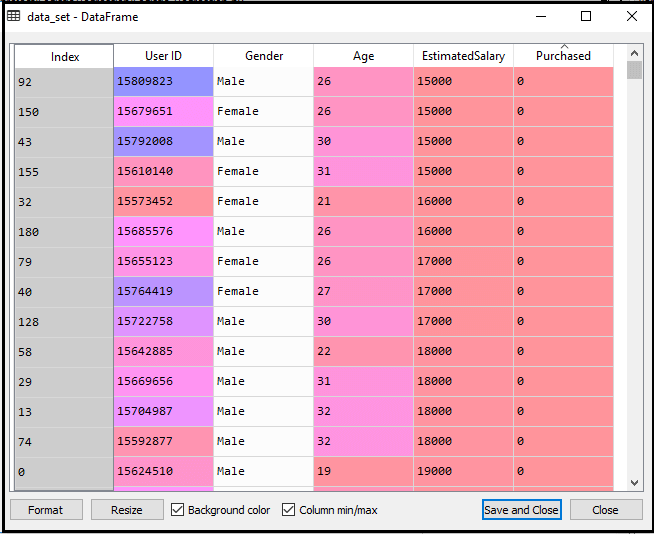 现在,我们将从给定的数据集中提取因变量和自变量。下面是它的代码: 在上面的代码中,我们用[2,3]表示x,因为我们的自变量是年龄和工资,它们位于索引2,3处。变量y取4因为因变量的下标是4。输出将是: 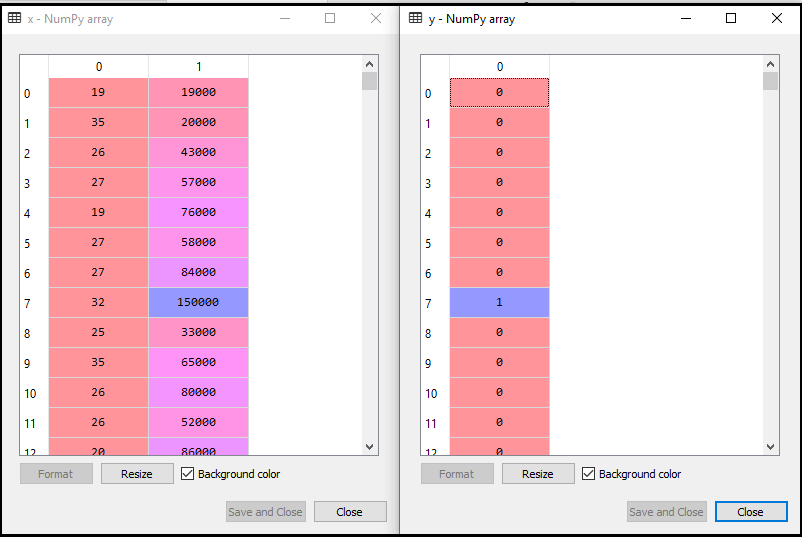 现在我们将数据集分成训练集和测试集。下面是它的代码: 它的输出如下所示: 对于测试集: 对于训练集: 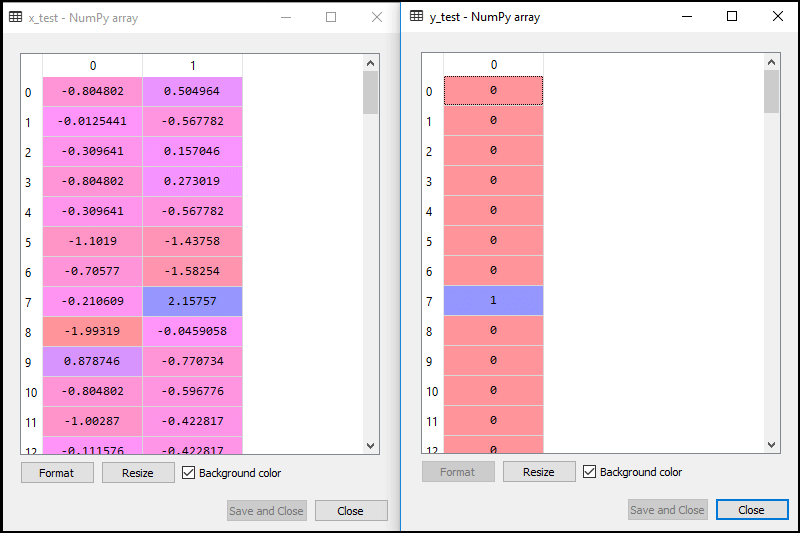 在逻辑回归中,我们会做特征缩放,因为我们想要准确的预测结果。这里我们只缩放自变量因为因变量只有0和1的值。下面是它的代码: 缩放后的输出如下:  2.训练集的逻辑回归拟合: 我们已经准备好了我们的数据集,现在我们将使用训练集来训练数据集。为了提供训练或将模型拟合到训练集,我们将导入LogisticRegression类sklearn图书馆。 在导入类之后,我们将创建一个分类器对象,并使用它将模型拟合到逻辑回归中。下面是它的代码: 输出:通过执行上面的代码,我们将得到下面的输出: [5]: 因此,我们的模型很好地拟合了训练集。 3.预测测试结果 我们的模型在训练集上得到了很好的训练,所以我们现在将通过使用测试集数据来预测结果。下面是它的代码: 在上面的代码中,我们创建了y_pred向量来预测测试集的结果。 输出:通过执行上面的代码,将在变量explorer选项下创建一个新的向量(y_pred)。可以看作是: 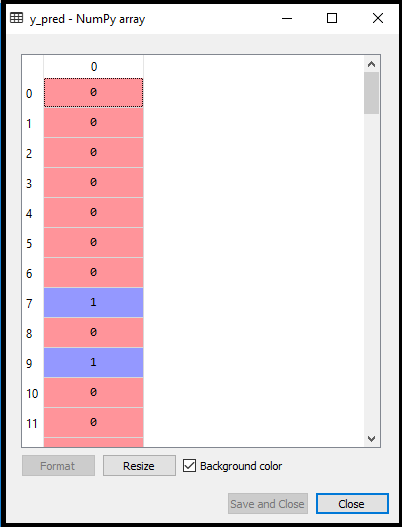 上面的输出图像显示了相应的预测用户,他们想购买或不购买汽车。 4.测试结果的准确性 现在我们将在这里创建混淆矩阵来检查分类的准确性。要创建它,我们需要导入confusion_matrixsklearn库的功能。在导入函数之后,我们将使用一个新变量来调用它厘米.该函数主要有两个参数y_true(实际值)和y_pred(分类器返回的目标值)。下面是它的代码: 输出: 通过执行上面的代码,将创建一个新的混淆矩阵。考虑下面的图片: 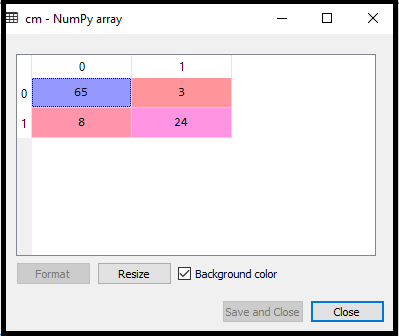 通过对混淆矩阵的解释,可以发现预测结果的准确性。通过以上输出,我们可以理解为65+24= 89(正确输出),8+3= 11(错误输出)。 5.可视化训练集结果 最后,我们将训练集结果可视化。为了可视化结果,我们将使用ListedColormapmatplotlib库的类。下面是它的代码: 在上面的代码中,我们导入了ListedColormapMatplotlib库的类来创建用于可视化结果的颜色图。我们创建了两个新变量x_set和y_set来代替x_train和y_train.在那之后,我们使用了nm.meshgrid命令创建一个矩形网格,其范围为-1(最小)到1(最大)。我们所取的像素点分辨率为0.01。 为了创建填充轮廓,我们使用mtp.contourf命令,它将创建提供颜色(紫色和绿色)的区域。在这个函数中,我们传递了classifier.predict显示分类器预测的数据点。 输出:通过执行上面的代码,我们将得到下面的输出: 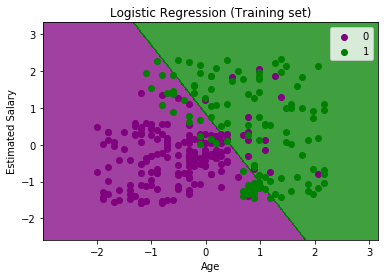 该图表可以用以下几点来解释:
分类器的目标: 我们已经成功地将训练集结果可视化,用于逻辑回归,我们的分类目标是划分购买SUV汽车的用户和未购买SUV汽车的用户。因此,从输出图中,我们可以清楚地看到两个区域(紫色和绿色)的观察点。紫色区域是没有购买汽车的用户,绿色区域是购买了汽车的用户。 线性分类器: 从图中可以看出,分类器本质上是直线或线性的,因为我们使用线性模型进行逻辑回归。在进一步的主题中,我们将学习非线性分类器。 可视化测试集结果: 我们的模型使用训练数据集进行了很好的训练。现在,我们将可视化新的观察结果(测试集)。测试集的代码将与上面相同,只是这里我们将使用X_test和y_test而不是X_train和y_train.下面是它的代码: 输出: 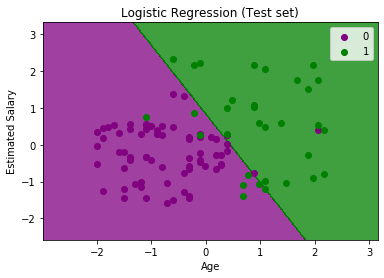 上图显示了测试集的结果。正如我们所看到的,图表被分为两个区域(紫色和绿色)。绿色的观测值在绿色区域,紫色的观测值在紫色区域。所以我们可以说这是一个很好的预测和模型。一些绿色和紫色的数据点位于不同的区域,可以忽略,因为我们已经使用混淆矩阵计算了这个误差(11个不正确的输出)。 因此,我们的模型非常好,可以为这个分类问题做出新的预测。
下一个话题
k -最近邻(KNN)算法
|
 视频加入我们的Youtube频道:现在加入
视频加入我们的Youtube频道:现在加入
反馈
- 将你的意见发送至(电子邮件保护)
帮助别人,请分享








