|
|

数据科学与机器学习的区别数据科学是研究数据清理、准备和分析机器学习是人工智能的一个分支,也是数据科学的一个子领域。数据科学和机器学习是两种流行的现代技术,它们正以不节制的速度发展。但这两个流行语,以及人工智能和深度学习是非常令人困惑的术语,所以了解它们之间的区别是很重要的。在本主题中,我们将了解数据科学和机器学习之间的区别,以及它们之间的关系。 数据科学与机器学习彼此密切相关,但具有不同的功能和不同的目标。乍一看,数据科学是一个研究从原始数据中寻找见解的方法的领域。然而,机器学习是一种由数据科学家使用的技术,使机器能够从过去的数据中自动学习。为了深入理解它们之间的区别,让我们首先简要介绍一下这两种技术。 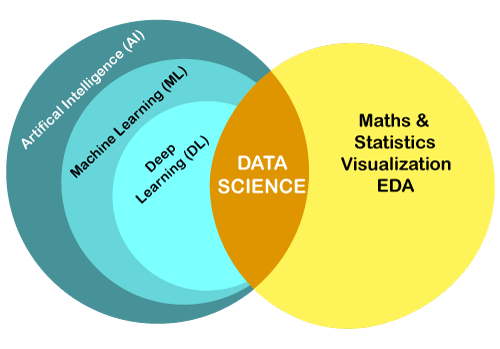 注意:数据科学和机器学习彼此密切相关,但不能被视为同义词。什么是数据科学?数据科学,顾名思义,就是关于数据的。因此,我们可以将其定义为:“一个对数据进行深入研究的领域,包括从数据中提取有用的见解,并使用不同的工具、统计模型和机器学习算法处理这些信息。”它是一个用于处理大数据的概念,包括数据清洗、数据准备、数据分析和数据可视化。 数据科学家从各种来源收集原始数据,准备和预处理数据,并应用机器学习算法,预测分析从收集的数据中提取有用的见解。 例如,Netflix使用数据科学技术通过挖掘用户的数据和观看模式来了解用户的兴趣。 成为数据科学家所需的技能
什么是机器学习?机器学习是人工智能的一部分,也是数据科学的子领域。这是一项正在发展的技术,它使机器能够从过去的数据中学习并自动执行给定的任务。可以定义为: 机器学习允许计算机自己从过去的经验中学习,它使用统计方法来提高性能并预测输出,而无需明确编程。 ML的流行应用有垃圾邮件过滤,产品推荐,在线欺诈检测等. 机器学习工程师必备技能:
机器学习在数据科学中的应用?机器学习在数据科学中的应用可以通过数据科学的开发过程或生命周期来理解。数据科学生命周期中的不同步骤如下: 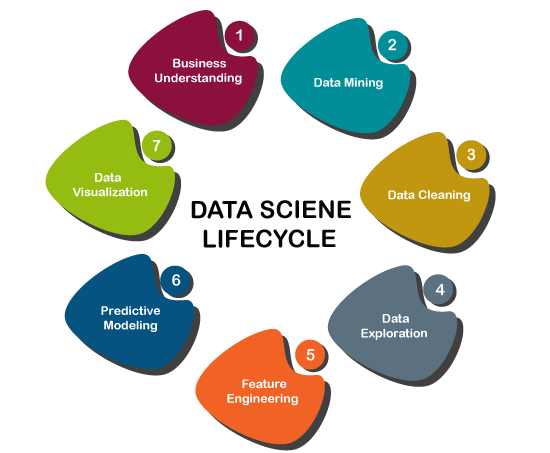
数据科学与机器学习的比较下表描述了数据科学和机器学习之间的基本区别:
下一个话题
机器学习vs深度学习
|
 视频加入我们的Youtube频道:现在加入
视频加入我们的Youtube频道:现在加入
反馈
- 将你的意见发送至(电子邮件保护)
帮助别人,请分享








