|
|

在机器学习层次聚类分层聚类是另一个无监督的机器学习算法,用于无标号数据集分组到一个集群,也被称为层序聚类分析或杂环胺。 在该算法中,我们发展集群的层次结构树的形式,这就是所谓的树状结构系统树图。 有时候k -均值聚类和层次聚类的结果看起来类似,但他们都不同取决于他们是如何工作的。由于没有要求预先确定集群的数量,因为我们做的k - means算法。 层次聚类方法有两种方法:
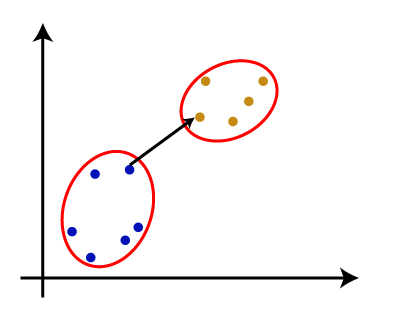
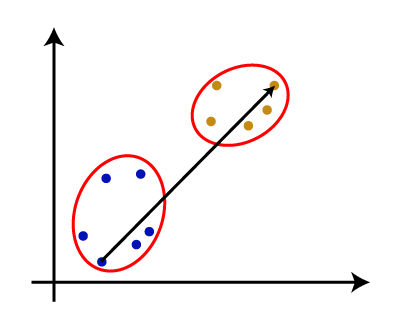
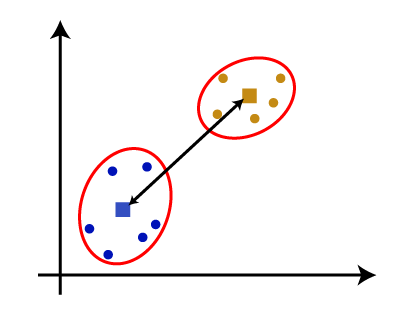
为什么层次聚类?我们已经有其他聚类算法等k - means聚类,那么为什么我们需要层次聚类?所以,正如我们所看到的k - means聚类算法有一些挑战,这是预定数量的集群,它总是试图创建集群的大小相同。解决这两个问题,我们可以选择的层次聚类算法,在该算法中,我们不需要预定义的知识集群的数量。 在这个主题中,我们将讨论会凝聚的层次聚类算法。 会凝聚的层次聚类会凝聚的层次聚类算法是一种受欢迎的HCA的例子。组数据集到集群,它遵循了自底向上的方法。这意味着,该算法认为每个数据集作为一个集群在一开始,然后开始结合集群的最亲密的一对在一起。它,直到所有的集群都合并到一个集群包含所有数据集。 这种层次的集群系统树图的形式表示。 如何会凝聚的层次聚类的工作吗?AHC算法的工作可以解释使用以下步骤:
注意:为了更好的理解层次聚类,建议看看k - means聚类措施之间的距离两个集群正如我们所见,最亲密的距离两个集群之间的层次聚类是至关重要的。有多种方法来计算两个集群之间的距离,而这些决定的规则聚类方法。这些措施被称为联系方法。下面给出的一些受欢迎的联系方法:
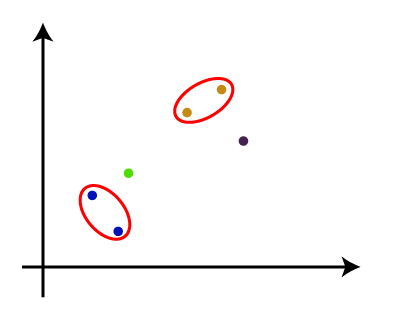
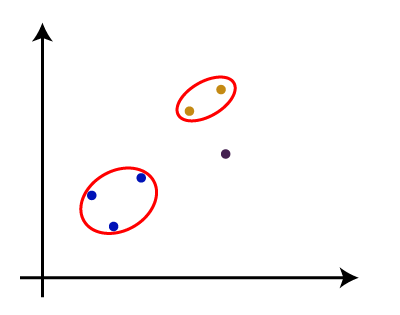
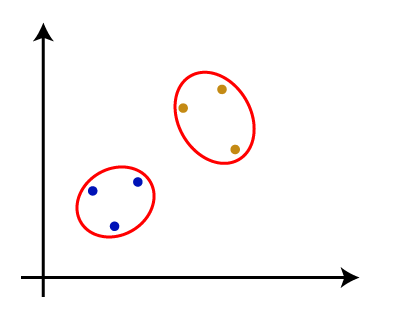
从above-given方法,我们可以应用的根据问题的类型或业务需求。 沃金的系统树图层次聚类系统树图是树状结构,这主要是用于存储记忆,HC算法每一步执行。系统树图的情节,y轴显示数据点之间的欧几里得距离,和x轴显示所有给定的数据集的数据点。 系统树图的工作可以解释使用下面的图: 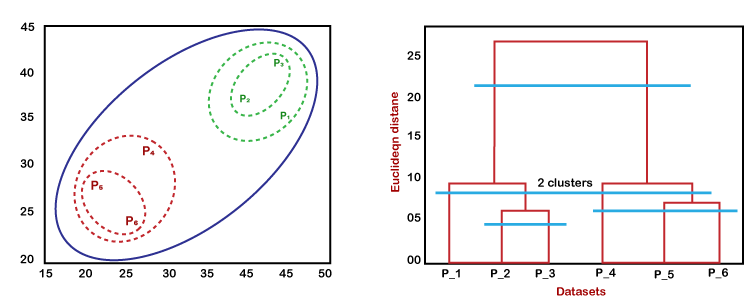 在上面的图中,左边部分是展示如何创建在烧结的集群,集群和正确的部分是显示相应的系统树图。
我们可以减少各级系统树图树结构按我们的要求。 Python会凝聚的层次聚类的实现现在我们将看到实际使用Python会凝聚的层次聚类算法的实现。要实现这一点,我们将使用相同的数据集的问题,我们已经使用在前面的k - means聚类的话题,我们可以比较两个概念很容易。 数据集包含的信息的客户参观购物中心购物。商场所有者想找一些或一些特定的行为模式的客户使用数据集信息。 使用Python AHC的步骤实现:实现的步骤将是相同的k - means聚类,除了一些变化等方法找到集群的数量。下面的步骤:
数据预处理步骤:在这一步中,我们将为我们的模型导入库和数据集。
上面的代码行用于导入库来执行特定的任务,如numpy数学运算,matplotlib用于绘制图表或散点图,熊猫导入的数据集。
正如上面所讨论的,我们已经导入相同的数据集Mall_Customers_data.csv,当我们在k - means聚类所做的那样。考虑下面的输出: 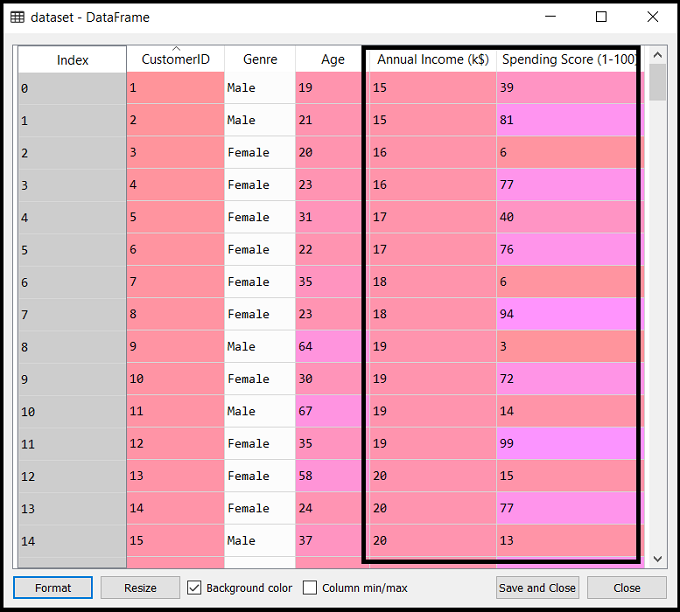
这里我们只提取矩阵的特性,我们没有任何进一步的因变量的相关信息。代码如下所示: 这里有只提取3和4列,我们将使用一个2 d图查看集群。因此,我们正在考虑年度收入和支出得分矩阵的特性。 第二步:找到最优数量的集群使用系统树图现在我们将找到最优数量的集群使用的系统树图模型。为此,我们将使用scipy图书馆,因为它提供了一个函数,将直接返回我们的代码的系统树图。考虑下面的代码: 在上面的代码行,我们已经导入了层次结构scipy库的模块。这个模块提供了我们一个方法shc.denrogram (),这需要链接()作为参数。连杆函数用于定义两个集群之间的距离,这里我们通过了x(矩阵的特性),和方法”病房”流行的链接在层次聚类的方法。 其余的代码行来描述系统树图的标签。 输出: 通过执行上面的代码,我们将得到下面的输出: 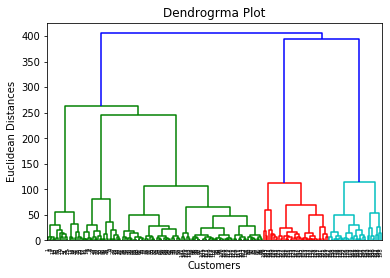 使用这个系统树图,现在我们将决定我们的模型的最优数量的集群。为此,我们会找到的最大垂直距离这并不减少任何单杠。考虑下面的图: 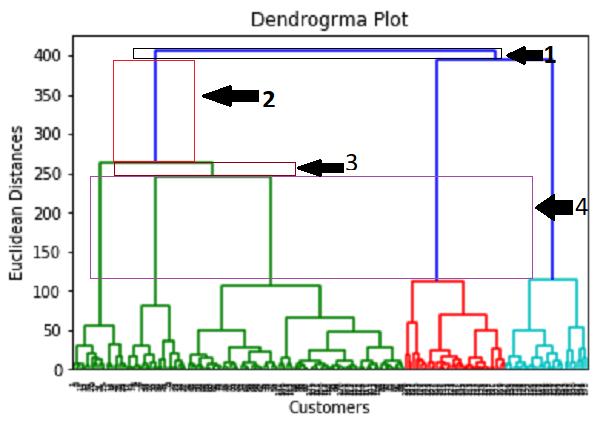 在上面的图中,我们展示了垂直距离不削减单杠。我们可以想象,4th距离是最大的,所以根据这个,集群的数量将是5(这个范围的竖线)。我们也可以把2nd数量大约等于4th距离,不过我们将考虑5集群因为相同的计算k - means算法。 所以,最优数量的集群将5,我们将在下一步训练模型,使用相同的。 步骤3:训练层次聚类模型我们知道所需的最优数量的集群,我们现在可以训练我们的模型。下面的代码是: 在上面的代码中,我们已经导入了AgglomerativeClustering类的集群模块scikit图书馆学习。 然后我们创建这个类的对象命名hc。AgglomerativeClustering类接受以下参数:
在最后一行中,我们已经创建了因变量y_pred适合或火车模型。它不仅训练模型,也返回每个数据点所属的集群。 执行上面的代码后,如果我们通过变量explorer选项Sypder IDE,我们可以检查y_pred变量。我们可以比较与y_pred变量原始数据集。考虑下面的图片: 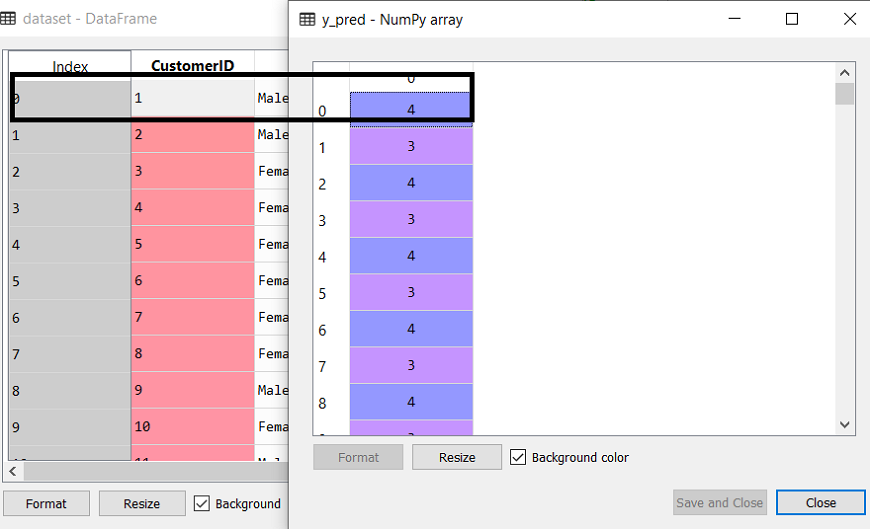 在上面的图片中,我们可以看出y_pred显示集群值,这意味着客户id 1属于5th集群(索引从0开始,所以4意味着5th集群),客户id 2属于4th集群,等等。 步骤4:可视化集群训练我们的模型成功,现在我们可以想象相对应的集群数据集。 在这里我们将使用相同的代码行是在k - means聚类,除了一个变化。在这里我们不会阴谋的重心在k - means,因为这里我们使用系统树图来确定最优数量的集群。下面的代码是: 输出:通过执行上面的代码行数,我们将得到下面的输出: 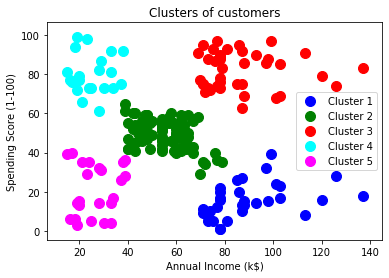
下一个话题
k - means聚类算法
|
 加入我们的Youtube频道视频:现在加入
加入我们的Youtube频道视频:现在加入
反馈
- 把你的反馈(电子邮件保护)
帮助别人,请分享








