|
|
Python教程
Python哦
Python MySQL
Python MongoDB
Python SQLite
Python的问题
Python Tkinter (GUI)
Python网页拦截器
Python MCQ
相关教程
Python程序

Python中的Box-Cox变换在我们的环境中,数据是随机分布的,其中一些数据是指数据集曲线的峰值,而一些数据点是指曲线的尾部。对于任何数据集,我们都可以使用其方差和均值来计算分布,并且我们可以看到数据分布到均值的距离。 通常,我们可以将数据的分布分为两种方式:
正态分布在这种分布中,数据沿均值的分布是非常一致的。在这里,我们得到曲线的峰值贯穿于平均值,数据沿平均值对称分布。 我们可以很容易地实现对正态分布数据的分析技术。 幂律分布在这种类型的分布中,对于一些小数据集,我们会看到曲线的峰值,然后对于大量数据集,我们会看到曲线的长尾。 但在环境中,数据的性质并不总是正态分布的。因此,在box-cox变换的帮助下,我们可以用一些数学公式将幂律分布的数据转化为正态分布的数据。 变换的数学分析是,我们将找到这样的值,即非正态分布的变换尽可能接近正态分布的数据集。 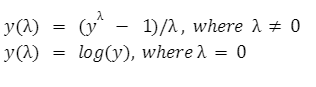 为了实现box-cox转换,我们将使用scipy库,函数将是scipy.stats.boxcox()函数。 语法:InputArray 这是我们想要转换成正态分布的数据集。 λ 如果lambda为none,我们将找出使value log函数最大的lambda值,如果它不是none,则对lambda的值执行转换。 α 这是一个可选参数,它接受0.0到1.0之间的浮点值。如果lambda为none,则考虑它,如果lambda不是none,则忽略它。 优化器 它是一个可选的可调用参数,在需要时调用。当lambda的值为none时,则使用此优化器查找使日志函数最小的lambda值。 例子:在这个例子中,我们将采用非正态分布的数据集,然后将其转换为正态分布的数据集。 输出: 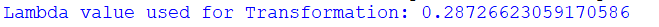 解释: 在上面的代码中,首先,我们在文件中导入了所需的模块,如numpy、scipy、matplotlib和seaborn,以绘制曲线。现在借助numpy的随机函数,我们创建了1200个数据点的随机数据集。现在我们使用boxcox()函数,该函数将数据集作为参数并返回转换后的数据集和lambda值。 现在使用histplot()函数,绘制原始数据集的曲线并对数据集进行转换。histplot()函数以数据集为参数,它有许多属性,如颜色,线宽等,这些属性定义了曲线的规格。现在使用show()函数,我们已经显示了变换前和变换后的曲线。 对于上面的随机数据集,我们得到的lambda值为0.2872,几乎等于0.28。 因此,在数据集中,新值将根据以下公式: 新值=(旧值0.2872 -1)/0.2872
下一个话题
Python中的AssertionError
|
 视频加入我们的Youtube频道:现在加入
视频加入我们的Youtube频道:现在加入
反馈
- 将你的意见发送至(电子邮件保护)
帮助别人,请分享








