|
|

Python中的Arima模型时间序列预测导论在常数时间间隔上记录度量的序列称为时间序列. 根据频率的不同,时间序列可以分为以下几类:
一旦我们完成了时间序列分析,我们必须对其进行预测,以预测该序列将会采取的未来值。 然而,预测有什么必要呢? 由于预测时间序列(如销售和需求)通常具有难以置信的商业价值,这增加了预测的需求。 时间序列预测通常用于许多制造公司,因为它驱动主要业务计划,采购和生产活动。任何预测的错误都会在整个供应链或任何业务框架中波动。因此,为了得到准确的预测,节省成本,这是非常重要的,是成功的关键。 时间序列预测背后的概念和技术也可以应用于任何行业,包括制造业。 时间序列预测可以大致分为两类:
在接下来的教程中,我们将了解一种被称为ARIMA建模. 自回归综合移动平均,缩写为华宇电脑,是一种预测算法,其核心概念是仅利用时间序列的前一个值中的数据来预测未来的值。 让我们详细了解ARIMA模型。 ARIMA模型简介华宇电脑,缩写为“自回归综合移动平均”,是一类模型,它根据给定的时间序列的先前值“演示”:它的滞后和预测中的滞后误差,因此可以利用这个方程来预测未来的值。 我们可以模拟任何非季节的时间序列,显示模式,而不是随机白噪声ARIMA模型. ARIMA模型有三个术语: P q d 在那里,
如果一个时间序列具有季节性模式,我们必须插入季节性周期,它就变成了SARIMA,简称“季节性ARIMA”. 现在,在理解之前AR项的顺序,让我们讨论一下d项。 在ARIMA模型中,'p'、'q'和'd'是什么?首要步骤是使时间序列平稳以建立ARIMA模型。这是因为这个术语“汽车倒退”在ARIMA中隐含了一个使用滞后作为预测因子的线性回归模型。正如我们已经知道的,线性回归模型适用于独立和不相关的预测因素。 为了使级数平稳,我们将使用最常用的方法,即从现值中减去过去的值。有时,根据级数的复杂程度,可能需要多次减法。 因此,d的值是使级数平稳所需的最小减法数。如果时间序列已经是平稳的,那么d就变成0。 现在,让我们来理解这些术语。p和"问”。 “p的顺序“AR”(自动回归)术语,即Y的滞后数作为预测因子。同时,”问的顺序MA(移动平均线)术语,这意味着在ARIMA模型中应该使用滞后预测误差数。 现在,让我们详细了解“AR”和“MA”模型是什么。 理解自回归(AR)和移动平均(MA)模型在下一节中,我们将讨论AR和MA模型以及这些模型的实际数学公式。 纯AR(仅自回归)模型是一种仅依赖于自身滞后的模型。因此,我们也可以得出结论,它是Y滞后的函数t' 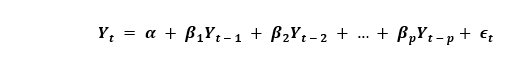 在那里,Yt - 1是这个系列的最后一个。β1为lag1的系数,为模型计算的截距项。 类似地,纯移动平均线(纯移动平均线)模型是一个Yt仅依赖于滞后预测误差。 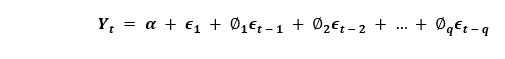 其中,误差项为对应滞后的AR模型误差。误差的住所t和ϵt - 1以下公式的误差为: 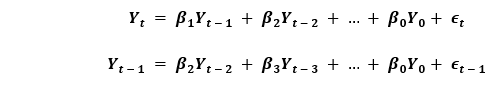 因此,我们分别总结了自回归(AR)和移动平均(MA)模型。 现在让我们理解ARIMA模型的方程式。 ARIMA模型是一种将时间序列至少减去一次以使其平稳的模型,我们将自回归(AR)和移动平均(MA)项结合起来。因此,我们得到如下方程: 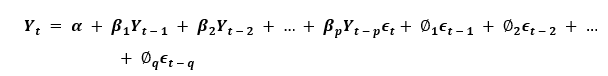 ARIMA模型: 预测Yt=常数+ Y的线性组合滞后(最多p个滞后)+滞后预测误差的线性组合(最多q个滞后) 因此,该模型的目标是找到的值p, q,d.然而,我们怎么才能找到一个呢? 让我们从找到' d '在ARIMA模型中。 求ARIMA模型中“d”的差分顺序在ARIMA模型中差分的主要目的是使时间序列平稳。 但是,我们必须注意不要对级数进行过差分,因为过差分的级数也可能是平稳的,这将影响以后模型的参数。 现在,让我们理解适当的差分顺序。 最合适的差分顺序是为了实现一个几乎平稳的序列围绕一个定义的平均值漫游和ACF平板相对更快地达到零所需的最小差分。 如果自相关性对于多个滞后(通常为10个或更多)为正,则该系列需要进一步差分。相反,如果滞后1自相关相当负,那么级数可能是过差的。 当我们不能在两个差分级数之间做出选择时,我们就必须选择差分级数中标准差最小的那个。 让我们考虑一个例子来检验级数是否平稳。我们将使用增强迪基-富勒检验(adfuller())从statsmodels包的Python编程语言. 例子: 输出: 增强Dickey-Fuller统计量:-2.464240 p值:0.124419 解释: 在上面的示例中,我们导入了adfuller模块一起使用numpy的日志模块和熊猫.然后我们用了熊猫库来读取CSV文件。然后我们用了adfuller方法,并将值打印给用户。 有必要检查级数是否平稳。如果不能,我们就得用差异;别的,d就变成了零. 的增强迪基-富勒(ADF)检验的零假设是时间序列不是平稳的。因此,如果ADF检验的p值小于显著性水平(0.05),那么我们将拒绝原假设,并推断时间序列肯定是平稳的。我们可以观察到,p值比显著性水平更显著。因此,我们可以对级数进行差分,并检查自相关图如下所示。 例子: 输出: 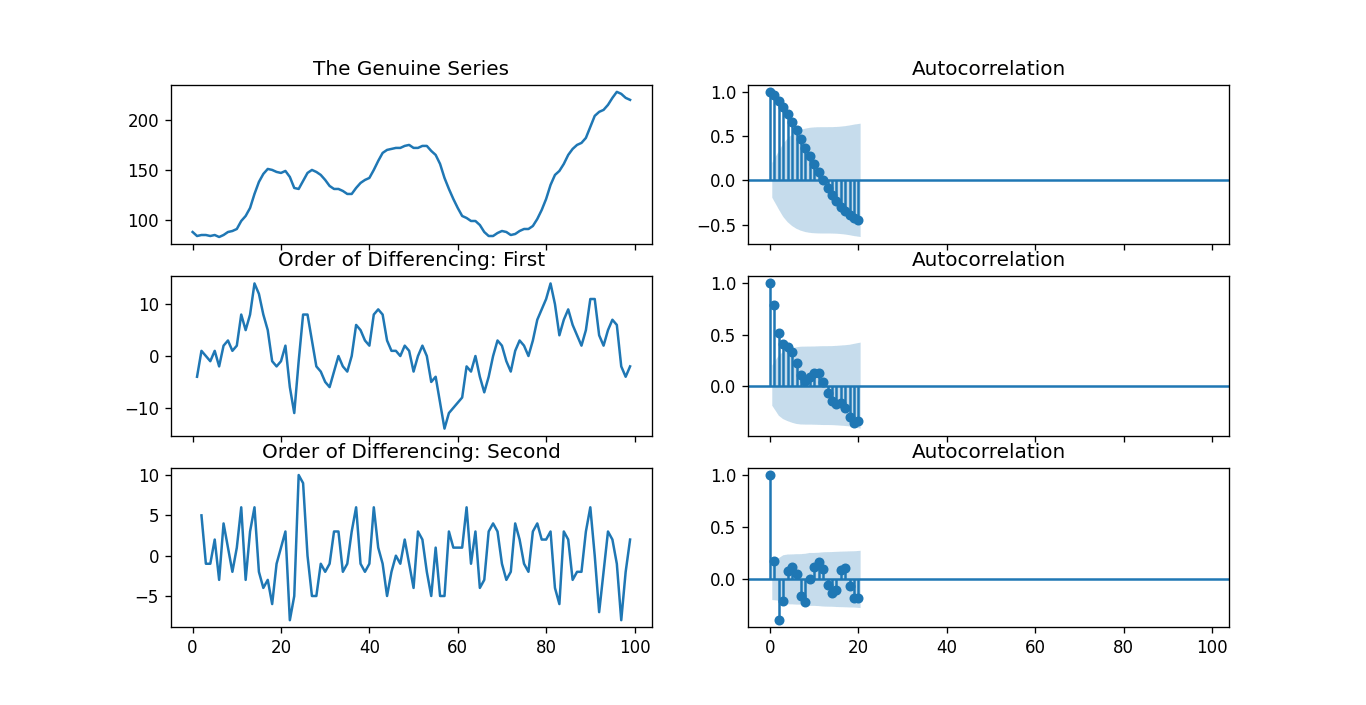 解释: 在上面的例子中,我们已经导入了所需的库和模块。然后,我们导入数据并绘制不同的图形。我们绘制了原始的级数图、一阶差分和二阶差分以及它们的自相关图。我们可以观察到,时间序列已经达到了两个不同阶的平稳性。然而,当我们看一下二阶差分的自相关图时,滞后进入远负区域的速度相当快,这表明该系列可能已经过度差分了。 因此,我们将暂时固定差分顺序,因为级数不是适当平稳的,或者我们可以说级数具有弱平稳性。 这可以如下所示。 例子: 输出: ADF测试= 2 KPSS测试= 0 PP测试= 2 解释: 在上面的示例中,我们导入了ndiffs方法pmdarima模块。然后导入数据集,并将'X'定义为包含数据集值的对象。我们使用ndiffs方法执行ADF、KPSS和PP测试,并将结果打印给用户。 寻找自回归(AR)项(p)的顺序在下一节中,我们将讨论检查模型是否需要任何操作的步骤自回归(AR)术语.所需要的AR术语的数量可以通过研究部分自相关(PACF)图. 我们可以考虑偏自相关作为序列和它的滞后之间的相关性一旦我们排除了中间滞后的贡献。因此,PACF倾向于传达序列与其滞后之间的纯粹相关性。因此,我们可以确定在自动回归(AR)项中是否需要延迟。 序列的滞后偏自相关(k)是Y的自回归方程中滞后的系数。 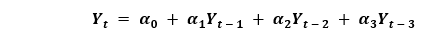 现在,让我们理解如何求出AR项的个数? 如我们所知,平稳序列中的任何自相关都可以通过插入足够多的AR项来修正。因此,我们最初可以将自回归(AR)项的顺序等同于PACF图中跨越显著性极限的滞后数。 例子: 输出: 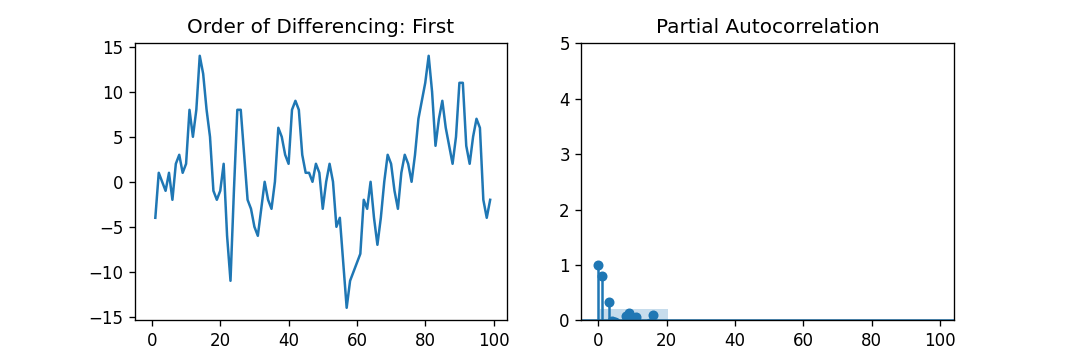 解释: 在上面的例子中,我们已经导入了所需的库、模块和数据集。然后,我们绘制了图来表示一阶差分及其部分自相关。 因此,我们可以观察到PACF滞后1在显著性线以上是相当显著的。滞后2似乎也很可观,完全保持跨越显著性极限(蓝色区域)。然而,我们将保守地将p暂时固定为1。 求移动平均线(MA)项(q)的阶数类似于我们之前在PACF图中看到的自回归(AR)项的数量,我们可以使用ACF图来找到移动平均(MA)项的数量。理论上,移动平均线(MA)项是滞后预测的误差。 ACF图表示在平稳序列中去除自相关所需的移动平均(MA)项的数量。 让我们考虑下面的例子来理解差分级数的自相关图。 例子: 输出: 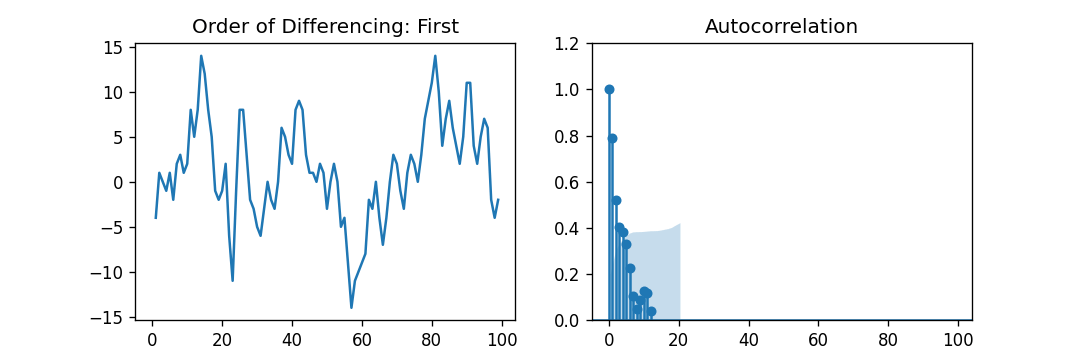 解释: 在上面的例子中,我们已经导入了所需的库、模块和数据集。然后,我们绘制了图来表示一阶差分及其自相关。因此,我们可以观察到一些滞后是相当高于显著性线。我们暂时把q设为2。如果有任何疑问,我们也可以使用更简单的模型来充分演示Y。 处理略低于或过差的时间序列有时,可能会出现这样的情况,即该级数略有差异不足,而将其额外差异一次则会使该级数在某种程度上过度差异。在这种情况下,我们必须为略有差异的时间序列添加一个或多个额外的自回归(AR)项,并为略有差异的时间序列添加一个额外的移动平均(MA)项。 一旦我们讨论了大部分主题,让我们开始创建时间序列预测的ARIMA模型。 建立ARIMA模型一旦我们确定了p、q和d的值,我们将尝试创建ARIMA模型。实施华宇电脑()模块如下所示: 例子: 输出: ARIMA模型结果 ============================================================================== 管理。变量:D.value不。观察:99模型:ARIMA(1, 1, 2)日志可能性-253.790方法:css-mle s.d创新3.119日期:星期四,2021年4月15日AIC 517.579时间:21:10:37 BIC 530.555示例:1 HQIC 522.829 ================================================================================= z系数性病犯错z P > | | (0.025 - 0.975 ] --------------------------------------------------------------------------------- const 1.1202 1.290 0.868 0.385 -1.409 3.649 ar.L1.D。值0.6351 0.257 2.469 0.014 0.131 1.139 ma.L1.D。值0.5287 0.355 1.489 0.136 -0.167 1.224 ma.L2.D。价值-0.0010 0.321 -0.003 0.998 -0.631 0.629的根源 ============================================================================= 真正的虚模频率 ----------------------------------------------------------------------------- AR.1 1.5746 + 0.0000 j 1.5746 - 0.0000 MA.1 -1.8850 + 0.0000 1.8850 0.0000 545.5472 0.5000 MA.2 545.5472 + 0.0000 j ----------------------------------------------------------------------------- 解释: 在上面的例子中,我们导入了名为华宇电脑从statsmodels类,并创建顺序为1,1,2的ARIMA模型。然后,我们将模型的摘要打印给用户。正如我们所观察到的,模型的概述揭示了许多细节。中间的表格是系数表“系数”值充当相关项的权重。 我们还可以注意到MA2项的系数趋于零,而p值在“P > |z|”专栏是极其微不足道的。p值应该小于0.05,理想情况下对应的X是显著的。 现在,让我们尝试重建没有MA2项的模型。 例子: 输出: ARIMA模型结果 ============================================================================== 管理。变量:D.value不。观察:99模型:ARIMA(1 1 1)日志可能性-253.790方法:css-mle s.d创新3.119日期:星期四,2021年4月15日AIC 515.579时间:21:34:00 BIC 525.960示例:1 HQIC 519.779 ================================================================================= z系数性病犯错z P > | | (0.025 - 0.975 ] --------------------------------------------------------------------------------- const 1.1205 1.286 0.871 0.384 -1.400 3.641 ar.L1.D。值0.6344 0.087 7.317 0.000 0.464 0.804 ma.L1.D。价值0.5297 0.089 5.932 0.000 0.355 0.705的根源 ============================================================================= 真正的虚模频率 ----------------------------------------------------------------------------- AR.1 1.5764 + 0.0000 j 1.5764 - 0.0000 MA.1 -1.8879 + 0.0000 1.8879 0.5000 ----------------------------------------------------------------------------- 解释: 在上面的例子中,我们降低了模型的AIC,这实际上是很好的。我们还可以观察到AR1和MA1术语的“p -值”得到了改善,并且非常显著(<< 0.05)。 现在,让我们绘制残差图,以确保不存在常量均值和方差等模式。 例子: 输出: 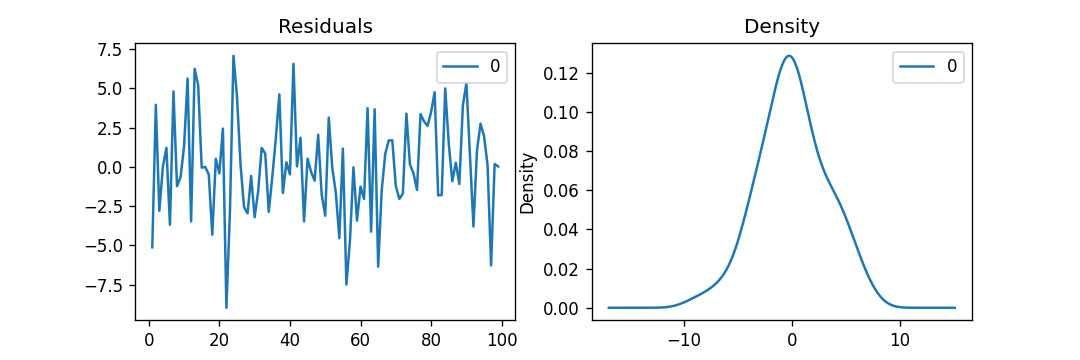 解释: 在上面的例子中,我们绘制了残差和密度图。我们可以观察到,残差看起来公平,接近零的平均值和一致的方差。函数的帮助下,让我们绘制表示实际值与拟合值的图形plot_predict ()函数。 例子: 输出: 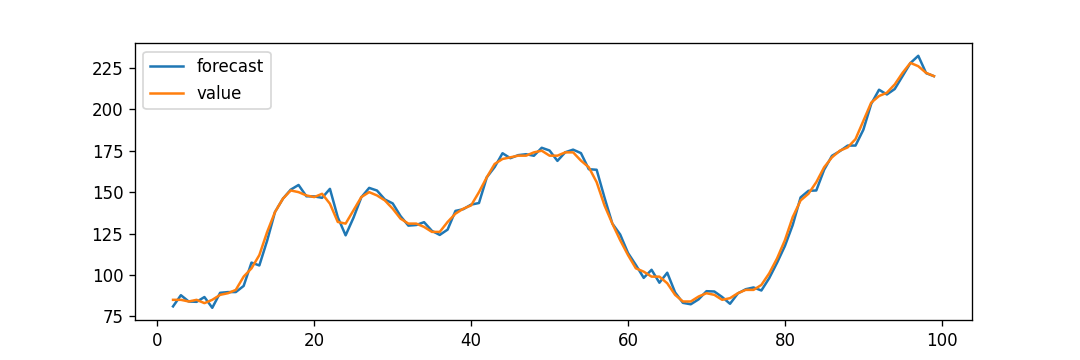 解释: 在上面的例子中,我们现在已经绘制了“实际与拟合”的图形和集dynamic = False.因此,利用样本内滞后值进行预测。 因此,模型得到训练,直到过去的值做出以下预测。因此,它可以创建拟合的预测,实际情况显得非常微妙。
下一个话题
Python模运算符
|
 观看视频请加入我们的Youtube频道:现在加入
观看视频请加入我们的Youtube频道:现在加入
反馈
- 将你的反馈发送至(电子邮件保护)
帮助他人,请分享








