|
|
Python教程
Python教程
Python特性
Python的历史
Python应用程序
Python安装
Python示例
Python变量
Python数据类型
Python的关键词
Python文字
Python运营商
Python的评论
Python如果其他
Python循环
Python For循环
Python While循环
Python打破
Python继续
Python通过
Python字符串
Python列表
Python元组
Python列表和元组
Python集
Python字典
Python函数
Python的内置函数
Python Lambda函数
Python文件I / O
Python模块
Python的例外
Python的日期
Python正则表达式
Python发送电子邮件
CSV文件读取
写CSV文件
读取Excel文件
写Excel文件
Python断言
Python列表理解
Python模块集合
Python数学模块
Python OS模块
Python模块随机
Python统计模块
Python系统模块
Python ide
Python数组
命令行参数
Python魔术方法
Python栈和队列
PySpark MLlib
Python装饰
Python发电机
使用Python Web抓取
Python JSON
出现Python Itertools
Python多处理
如何计算两个点之间的距离使用GEOPY
Gmail API在Python中
如何画出谷歌地图使用Python中的叶包
在Python中网格搜索
Python高阶函数
在Python中nsetools
Python程序找到第n个斐波那契数
Python OpenCV对象检测
Python SimpleImputer模块
在Python中第二大号码
Python哦
Python MySQL
Python MongoDB
Python SQLite
Python的问题
如何安装Python在Windows
如何扭转Python中的字符串
如何阅读Python CSV文件吗
如何运行Python程序
如何在Python中接受输入
如何在Python列表转换成字符串
如何添加元素列表中吗
如何在Python中比较两个列表
如何在Python将整数转换成字符串
如何在Python中创建一个字典
如何创建一个虚拟环境在Python中
如何在Python中声明一个变量
如何安装Python matplotlib
如何安装Python OpenCV
如何在同一行打印在Python中
如何在Python中读取JSON文件
如何在Python中读取一个文本文件
如何使用Python for循环
是Python脚本语言
学习Python需要多长时间
如何在Python中连接两个字符串
如何连接数据库在Python中
如何将列表在Python字典吗
如何在Python中声明一个全局变量
如何在Python中扭转号码
在Python中一个对象是什么
这是最快的Python实现
如何明确的Python shell
如何创建一个在Python DataFrames
如何开发一个游戏在Python中
如何安装Tkinter在Python中
如何在Python中画一个图
如何打印模式在Python中
如何在Python中从列表中删除一个元素
如何在Python中整数吗
如何在Python字典
在Python中强大的数
在Python中如何将文本转换为语音吗
在Python中冒泡排序
日志在Python中
在Python中插入排序
在Python中二分查找
在Python中线性搜索
Python vs Scala
队列在Python中
在Python中堆栈
在Python中堆排序
在python回文项目
python项目累计总和
在Python中归并排序
Python矩阵
Python的单元测试
取证和虚拟化
最好的书学习Python
最好的书学习Django
肾小球囊性肾病python的两个数字
Python程序生成一个随机的字符串
如何在一个炎热的编码序列数据在Python中
如何在Python中编写的平方根
指针在Python中
Python二维数组
Python的内存管理
Python库数据可视化
如何在Python中调用一个函数
Git在Python模块
Python框架游戏
Python音频模块
维基百科在Python模块
Python随机randrange ()
在Python中排列组合
在Python中Getopt模块
合并两个字典在Python中
多线程在Python 3
在Python中静态
当前日期在Python中怎么走吗
在Python中argparse
Python tqdm模块
在Python中凯撒密码
记号赋予器在Python中
如何在Python中添加两个列表
浅拷贝和深拷贝在Python中
原子Python
在Python中包含
在Python中标签的编码
Django JS和节点
Python框架
如何创建一个向量在Python中使用NumPy
泡菜的Python模块
如何在Python字节转换成字符串
Python程序找到回文构词法
如何将列表设置
Python与JavaScript
假期Python模块
FuzzyWuzzy Python库
Dask Python
Dask Python(第2部分)
在Python中模式
在Python中菜单驱动的程序
Python数组和列表
duck typing在Python中是什么
在Python中PEP 8
Python用户组
在Python中基本命令
F Python中的字符串
布立吞人是如何工作的
如何使用浏览器中的布立吞人吗
Arima模型在Python中
Python模数运算符
MATLAB与Python
在Python方法解析顺序
猴子在Python中修补
Python __call__方法
Python heapq模块
Python字符串
项目的想法Python初学者
Python骗子
在Python Fizz-Buzz项目
横膈Python
Python程序打印给定数量的主要因素
Python程序打印帕斯卡三角形
在Python中NamedTuple
在Python中OrderedDict
在Python中学习
Python返回语句
在Python Getter和Setter
在Python中枚举类
析构函数在Python中
在Python中曲线拟合
将CSV转换为JSON在Python中
在Python中下划线(_)
设置和在Python列表
定位和执行模块
平在Python列表
在Python中对情节
数据隐藏在Python中
Python程序可以找到两个列表的十字路口
如何创建要求。txt文件在Python中
在Python中井字
Python异步编程——asyncio和等待
Python main()函数
在Python strftime()函数
详细的国旗在Python中正则表达式
Python AST模块
Python模块- HTTP请求的请求
在Python中Shutil模块
Python时代Datetime
Python del声明
在Python中循环技术
元编程和Python中的元类
在Python中精密处理
Python加入列表
带()函数在Python中
梯度下降算法
在Python中Prettytable
在Python中情绪分析
Python列表转换为NumPy数组
在Python中回溯
在Python中时间时钟()方法
在Python中双端队列
在Python中字典理解
Python数据分析
Python寻求()方法
在Python中三元运算符
如何计算圆的面积使用Python吗
如何编写文本文件使用Python吗
Python KeyError
Python super()函数
max()函数在Python中
在Python中部分模块
流行的Python框架来构建API
如何检查Python版本吗
Python % s -字符串格式化
Python seaborn库
在Python中Countplot
range()与Python Xrange ()
在Python中Wordcloud包
dataframe转换成列表
Python中的方差分析测试
Python程序找到复利
在Python中Ansible
Python重要的技巧和窍门
Python协同程序
在Python中双下划线
VS re.findall re.search()()在Python中正则表达式
如何安装Python statsmodels
因为在Python中
vif在Python中
在Python中__add__方法
道德黑客与Python
类变量和实例
在Python中完全数
在Python中生物
Python程序将十六进制字符串转换为十进制字符串
不同的方法在Python中不使用第三个变量交换两个数
如何改变Matplotlib情节大小
如何让Python的邮政编码吗
鳗鱼在Python中
在Python中赋值操作符
语音识别python
Python中的收益和回报
石墨烯Python
在Python中名称改编
Python组合出现没有itertools
Python理解
在Python中InfluxDB
卡夫卡用Python教程
增强在Python中赋值表达式
Python (x, y)软件
Python事件驱动编程
Python信号量
Python反向排序
在Python中自同构的数量
在Python中运算符
Python程序接受的字符串包含所有元音
基于类的观点和基于函数的观点
如何处理在Django饼干吗
gg在Python()函数
在Python中亲和数
在Python中上下文管理器
使用Python创建体重指数计算器
Python中的字符串二进制
Python脚本模式是什么
机器学习的最佳Python库
Python程序显示日历的年份
如何打开URL在Python中
在Python中破管错误
在Python代码模板用于创建对象
Python程序计算的最佳时间买入和卖出股票
元组在Python字符串
Kadane在Python的算法
伐木工人在Django
天气在Django应用程序
缺失的数据难题:勘探和归责技术
数组在Python中旋转的不同方法
操作符重载在Python中是什么
在Python中Defaultdict
操作员在Python模块
转子部件kivy的Python库
车牌识别使用Python
模糊Python程序
将字符串转换为Python字典
Python中的字符串转换为JSON
Python中的DBSCAN算法
如何编写一个代码打印Python异常/错误等级
主成分分析(PCA)与Python
Python程序找到两个给定的日期之间的天数
使用Python对象识别
Python VLC模块
设置为在Python列表
Python中的字符串int
物联网与Python
Python pysftp模块
神奇的Python的黑客
平均在Python列表
检查安装Python模块
在Python中选择()
在Python列表转换为dataframe
Python中的字符串转换为浮动
在Python中修饰符和参数
在Python中动态类型
晶圆厂在Python中
如何在Python中去掉小数
Python关闭
Python水珠模块
写一个Python模块
在Python模块和包
在Python中SNMP模块
平均在Python列表
添加和扩展和插入在Python中
如何在Python中从列表中移除重复的
将多个字符从Python中的字符串
在Python中洗牌
地板()和装天花板在Python()函数
sqrt (): Python的数学函数
Python yfinance模块
在Python中Difflib模块
列类型的字符串转换成熊猫DataFrame Datetime格式
Python wxPython模块
随机均匀Python
关系运算符在Python中
Python中的字符串列表
聊天机器人在Python中
如何将浮在Python int
把所有的元素在Python列表
在Python模块和函数
反向Python中的元组
元组在Python字典
Python的datetime.timedelta()函数
Python生物模块
Python仪表板模块
如何选择行熊猫DataFrame基于条件
铸字在Python中
在Python中Dateutil模块
在Python中Getpass模块
Python魔杖库
生成一个二维码使用Python
最好的Python PDF库
Python Cachetools模块
Python Cmdparser模块
Python仪表板模块
Python Emoji模块
Python Nmap模块
Python PyLab模块
在Python中使用PDF文件
PDF在Python中处理
使用Python操纵PDF
列出所有从Python模块功能
Python字典列表
Python搁置模块
使用Python创建交互式PDF表单
Python报纸模块
如何连接无线网络使用Python吗
最好的Python库用于道德黑客
Windows系统管理管理使用Python
在Python中缩进的错误
Python imaplib模块
Python lxml模块
Python MayaVi模块
Python os.listdir()方法
Python模块的自动化
数据可视化在Python中使用散景库
如何绘制符号在谷歌地图在Python中使用散景库
如何画一个饼图在Python中使用散景库吗
如何阅读PDF在Python中使用OCR的内容吗
在Python中语法和拼写检查器
使用Python将HTML转换为PDF文件
readline在Python中
如何绘制图形在Python中使用散景多行吗
Python中的bokeh.plotting.figure.circle_x()函数
Python中的bokeh.plotting.figure.diamond_cross()函数
如何画射线图在Python中使用散景
图像隐写术使用Python
不一致的使用制表符和空格缩进
在Python中绘制多个地块使用散景如何
如何使一个区域的阴谋在Python中使用散景
Python ChemPy模块
Python内存分析器模块
Python phonenumber模块
Python平台模块
TypeError字符串索引必须是一个整数
时间序列预测与先知在Python中
Python Pexpect模块
Python Optparse模块
int对象不是iterable。Python矮小的库
一些Cryptocurrency Python库
建立一个区块链使用Python
霍夫曼编码使用Python
在Python中嵌套的字典
集合。在Python中UserString
如何自定义和Matplotlib传说吗
Matplotlib次要情节的传奇
Python形态学在图像处理操作
Python在人工智能的作用
Python Instagramy模块
Python pprint模块
Python PrimePy模块
安卓开发使用Python
Python fbchat库
人工智能网络安全:斑算法和算法
了解人工智能的识别模式
当在大数据和如何利用λ架构
为什么我们要学习Python数据科学
如何改变Matplotlib的“传奇”位置吗
如何检查是否在Python中元素存在于列表吗
如何检查给定单词的拼写在Python中使用附魔吗
Python程序计算两个字符串中匹配的字符数
乒乓球比赛在Python中使用龟
Python函数来显示日历
Python程序计算前n自然数的平方和
Python程序如何检查是否一个给定的数字是斐波那契数
Python中的randint()函数
在Python中使用Matplotlib和GDAL可视化Tiff文件
在Python中rarfile模块
使用Python阻止的话
Python程序字猜谜游戏
区块链医疗:创新和机会
在Python中使用龟模块蛇游戏
两个给定的整数之间如何找到阿姆斯特朗数字
芹菜使用Python教程
RSME——均方根误差在Python
建立一个推特机器人使用Python
Python Progressbar模块
Python发音模块
Python PyAutoGUI模块
Python Pyperclip模块
如何生成UUID在Python中
Python在2022年十大图书馆学习
阅读NetCDF数据使用Python
在Python的reprlib模块
如何把多个输入从用户在Python中
Python zlib库
Python队列模块
Python YAML解析器
在Python中有效根搜索算法
Python Bz2模块获取
Python IPaddress模块
Python PyLint模块
如何在Python中处理XML
在Python中平分算法功能
创建和更新幻灯片使用Python
如何改变图的大小和matplotlib画吗
在Python中键盘模块
Python Pyfiglet模块
在Python中创建一个MCQ测试游戏
与Python统计
吉尔在Python中是什么
基本的Python对于Java开发人员
如何使用Python脚本下载YouTube视频吗
交通流仿真在Python中
如何合并两个列表在Python中
Python中的元字符
编写Python程序打印整数的所有可能的组合
模Python中的字符串格式化
计数器在Python中
Python pyautogui库
如何绘制了曼德尔勃特集合在Python中
Python Dbm模块
摄像头运动检测器在Python中
在Django GraphQL实现
如何实现在Python Protobuf
PyQt图书馆在Python中
如何美化和漂亮的打印在Python中数据结构吗
在Python中使用bcrypt加密密码
在Python中金字塔框架
建立一个电报bot使用Python
在Python中Web2py框架
Python os.chdir()方法
平衡在Python中括号
如何在Python中提供多个构造函数类
分析的Python代码
建立一个Dice-Rolling与Python应用程序
电子邮件模块在Python中
在Python中必不可少的递归程序
如何设计Hashset在Python中
如何在Python中提取YouTube数据
如何解决股票使用Python跨度问题
在Python中选择排序
信息在Python中()函数
两个金额问题:Python和两个问题的解决方案列表
写一个Python程序检查列表包含重复的元素
编写Python程序来搜索排序数组中的一个元素
在Python中Pathlib模块
创建一个实时语音翻译使用Python
如何在Python Tuple
Python的优点,使它如此流行和其主要应用
图书馆在Python中
数据可视化在Python包
Python pympler库
在Python中SnakeViz图书馆
物化视图和视图
名称空间在Python中
Python程序返回数组的产品的标志
在Python中织物模块
在Python中Tracemalloc模块
分裂,在python中接头,Subn功能模块
在Python中机器人框架
与Python了解机器人
在Python中Gzip模块
古比鱼/ heapy Python
在Python中Microservices
在Python中Functools模块
策划谷歌地图在Python中使用gmplot包
监控设备使用Python
在Python中浏览器模块
二叉搜索在Python中使用递归
C和c++和Python和Java
如何检查Python的版本吗
Python列表理解
罗马数字转换为十进制(整数)|编写Python程序将罗马转换为整数
创建REST API使用Django框架休息| Django框架教程
记忆在Python中使用修饰符
Python的网络工程
在Python”和“与”&”
在Python中加密包
刽子手在Python中游戏
使用Python实现的线性回归
在Python中嵌套的修饰符
Python程序找到两个字符串之间的区别
Python urllib库
菲奥娜在Python模块
在python中重火力点模块
Python对孩子
在Python中地板部门
十大最佳Coursera Python课程
Python为网络工程库
如何分词文本、句子、单词有用吗
如何导入数据集使用sklearn PyBrain吗
使用TextBlob词性标记
Python对孩子:Python资源学习路径
在Python中XGBoost毫升模型
简单的火焰在Python中游戏
闹钟在Python GUI
石头纸剪刀在Python中游戏
检查是否一个给定的链表是循环链表
在Python中反向链接的列表
平()和拉威尔()Numpy函数
学习矢量量化
词元化和TextBlob标记
如何在Python中整数吗
运算符的优先级和结合性Python
Python非官方的库
12个最佳Python项目类12
在Python中桌面通知
如何处理在Python中时区
Python秘密模块
使记事本使用Tkinter
Camelcase在Python中
Python和Scala的区别
如何使用Python Cbind
Python断言
Python逐位运算符
Python时间asctime()方法
在Python中q学习的
在Python中遇到组合迭代器
类方法和静态方法和实例方法
Python免费电子书
八个神奇的Python Tkinter项目的想法
创建一个键盘记录器使用Python
在Python中Quandl包
在Python实现先验的算法
情绪分析使用维德
在Python中Break语句
处理不平衡数据在Python小姐打附近算法和算法
使用Python GUI计算器
在python中Sympy模块
击杀Python
在Python中广度优先搜索
Python Graphviz:点语言
如何想象一个神经网络在Python中使用Graphviz
Python Graphviz
复利计算器使用Python GUI
Rank-based百分位计算器在Python GUI
URL shortner在Python中
使用Python自动化Instagram消息
Python SimpleHTTPServer模块
标准Python GUI单位转换器
Python Paramiko模块
在Python中分派修饰符
在Python中自省
在Python中类修饰符
自定义解析器行为的Python模块“configparser”
Python的模块Configparser
在Python中使用Tkinter GUI日历
Python程序旋转图像
在Python中验证IP地址
编写一个程序,打印给定二维矩阵的对角元素
在Python中封装
多态性在Python中
在Python中StringIO模块
10 Python图像处理工具
通过Python如何插入current_timestamp Postgres吗
在Python中如何执行单向方差分析吗
Python类型的继承
Python的机械工程师
Python模块xxHash
在Python中转义序列
PYTHON空语句
Python和运营商
Python或运算符
Python位XOR运算符
Python新行
__init__在python中
在Python中__dict__
简单的待办事项清单在Python GUI应用程序
自动化软件测试与Python
自动化谷歌搜索使用Python
在Python中__name__
在Python中_name_ _main_
在Python 8困惑的问题
在Sklearn accuracy_score
Python与茱莉亚
Python Crontab模块
Python Shell命令执行
文件资源管理器使用Tkinter Python
在Python中自动交易
Python自动化项目的想法
k - means 1 d集群在Python中
添加一个键:值对Python字典
符合(),变换()和fit_transform Python中的()方法
Python的金融
在Python中Librosa图书馆
对于初学者来说Python人工智能项目
在Python中使用Tkinter年龄计算器
如何在Python迭代字典吗
如何在Python中遍历一个列表
如何学习Python在线吗
在Sklearn交叉验证
为金融行业流行的Python库
著名的Python认证,金融课程
在Sklearn Accuracy_Score
在Sklearn K-Fold交叉验证
Python项目毫升在金融中的应用
数字时钟在Python中使用Tkinter
在Python中相关矩阵
欧式距离使用NumPy
如何解析JSON在Python中
如何在Python中第一列索引
如何让一个应用在Python中
莫尔斯电码译者在Python中
Python蝗虫模块
Python时间模块
Sklearn线性回归的例子
时间的Python模块
二维码使用python
抛砖(记忆游戏)使用Python
Python旋度
Python旋度的例子
Sklearn模型选择
在Sklearn StandardScaler
在Python中过滤列表
Python项目网络
Python NetworkX
Sklearn逻辑回归
在Python中Sklearn是什么
Tkinter Python应用程序之间切换不同的页帧
追加(键:值)对字典
任何Python中的()
在Python中参数和参数
在Python中属性的含义
数据结构和算法在Python中|设置1
在Python中高斯消去法
学习Python 2022年从最好的YouTube频道
Sklearn集群
Sklearn教程
在Python中睡眠时间是什么
Python Word2Vec
创建GUI Marksheet使用Tkinter在Python中
在Python中使用Tkinter颜色游戏
简单的游戏在Python中使用Tkinter火焰
使用Python Tkinter YouTube视频下载器
在字典找到键的值
Sklearn回归模型
在Python中使用Tkinter COVID-19数据表示应用
图像查看器应用程序使用Tkinter在Python中
简单的注册表单使用Tkinter在Python中
Python字符串=
在Python中控制语句
如何绘制直方图在Python中
如何在Python情节多元线性回归
在Python中物理计算
解决使用Python物理计算问题
屏幕旋转GUI使用Python Tkinter
在Python中使用Tkinter应用程序搜索安装应用程序
拼写校正器GUI使用Tkinter在Python中
在Python中数据结构和算法
GUI关机,重启,注销电脑使用Tkinter在Python中
GUI中提取的歌词歌曲在Python中使用Tkinter
情绪探测器GUI使用Tkinter在Python中
Python睡眠()函数
使用机器学习糖尿病的预测
第一个独特的Python字符串中的字符
使用Python创建自己的电影推荐引擎
发现酒店价格使用酒店价格比较API使用Python
开始使用RabbitMQ和Python
如何在Python中发送推送通知
如何使用Python复述
前概念的Python Python开发人员
Pycricbuzz图书馆——板球Python API
编写Python程序结合两个字典共同的键值
Apache气流在Python中
在Python中局部套用
如何找到用户的位置使用地理定位API
在Python中LRU缓存
Python列表理解vs生成器表达式
Python的输出格式
Python房地产装饰
在Python DFS(深度优先搜索)
快API教程:一个框架来创建API
镜子Python中的字符串的字符
Python IMDbPY为电影——一个图书馆
Python在Python中打包和拆包参数
Python pdb教程——Python pdb
Python程序将所有零的数组
定期在Python字典vs有序字典
在Python中拓扑排序
与熊猫Tqdm集成
在Python中平分模块
Boruvka的算法——最小生成树
在Python中属性和属性的区别
画出伟大的印度国旗使用Python代码
在Python找到所有与零和三胞胎
在Python中使用tinyhtml生成HTML模块
谷歌搜索使用Python包
公里公里算法的算法,实现使用Python
Python 3.10的新特性
在Python类型的常数
写一个Python程序排序一个奇偶排序或奇偶换位
编写Python程序在相反的顺序打印双向链表
应用程序获得美元——INR比率在Python中使用Tkinter生活
创建第一个使用Python中的PyQt5 GUI应用程序
简单的GUI计算器在Python中使用PyQt5
最好的参考资料以了解NumPy和熊猫
在Python Sklearn决策树
Python书籍对数据结构和算法
Python Tkinter-Top水平小部件
将第一个字符从Python中的字符串
在Python中使用PyQt5贷款计算器
在Python中使用PyGame飞扬的鸟比赛
Rank-Based百分位计算器使用PyQt5 Python GUI
三维散射策划在Python中使用Matplotlib
在Python函数注释
Numpy-3d矩阵乘法
在Python中os.path.abspath()方法
新兴发展Python项目2022
如何检查Nan值在熊猫吗
在Python中如何结合两个dataframe——熊猫
如何让一个Python汽车遥控器吗
在Python中使用PyQt5年龄计算器
创建一个表在Python中使用PyQt5
使用Python中的PyQt5创建GUI的日历
在Python中使用PyGame蛇游戏
在Python中,函数返回两个值
学习Python完整的路线图
树视图控件,在Tkinter-Python树视图滚动条
AES CTR Python
Curdir Python
在Python中FastNlMeansDenoising
Python Email.utils
Python Win32进程
数据科学项目在Python中适当的项目描述
如何实践Python编程
假设Python测试
* * args, * * kwargs Python
Python中的__file__(一种特殊的变量)
在Python中__future__模块
Lambda函数应用到熊猫Dataframe
箱线图在Python中使用Matplotlib
在Python中Box-Cox转换
在Python中AssertionError
在字典找到关键与最大值
项目在Python中,乳腺癌与深度学习分类
在Python中使用PyQt5色彩游戏
数字时钟在Python中使用PyQt5
使用Python中的PyQt5倒数计时器
GUI关机,重启,注销电脑使用Tkinter在Python中
简单的火焰游戏在Python中使用PyQt5
树视图控件,在Tkinter-Python树视图滚动条
在Python中__getitem__ ()
GET和POST请求使用Python
在Python中AttributeError
在Python中Matplotlib.figure.Figure.add_subplot ()
Python一些功能int (bit_length to_bytes和from_bytes)
检查字符串是否在Python字符
如何在Python中得到2位小数
指数在Python列表元素怎么走吗
在Python中嵌套的元组
GUI助理在Python中使用Wolfram Alpha API
在Python中信号处理的
熊猫在Python中散射()阴谋
散射()情节matplotlib Python
在Python中数据分析项目的想法
建立一个记事本使用PyQt5和Python
简单的注册表单使用PyQt5 Python
Python中的条件表达式
如何打印没有括号在Python列表
如何在Python中重命名列名称
遍历DataFrame Python
音乐推荐系统Python项目源代码
Python计数器添加
Python项目源代码——在GitHub剖面仪
Python的算法
Python描述符
Python假
Python前端框架
Python javascript浏览器
Python剥绒机
在Python中令牌和字符集
在Python Web开发项目
Python是为什么如此受欢迎
使用Python的公司
如何学习Python更快呢
在Python中Legb规则
Python不和机器人
Python文档的最佳实践
Python移动应用开发
json文件保存在Python
划痕和Python基础知识
情绪分析使用NLTK
Python Tkinter (GUI)
Python Tkinter
Tkinter按钮,
Tkinter画布,
Tkinter Checkbutton
Tkinter条目,
Tkinter框架,
Tkinter标签,
Tkinter列表框,
Tkinter Menubutton
Tkinter菜单,
Tkinter消息,
Tkinter Radiobutton
Tkinter规模,
Tkinter滚动条,
Tkinter文本,
Tkinter最高级的,
Tkinter Spinbox
Tkinter PanedWindow
Tkinter LabelFrame
Tkinter对话框,
Python Web拦截器
Python MCQ
相关教程
NumPy教程
Django教程
瓶教程
熊猫教程
Pytorch教程
Pygame教程
Matplotlib教程
OpenCV教程
Openpyxl教程
Python CGI
Python的设计模式
Python程序

在Python Sklearn决策树使用机器学习算法称为决策树,我们可以代表了选择和决定的潜在后果,包括输出、输入成本,和公用事业。 监督学习方法组包括决策算法。它的工作原理与分类和连续的输出参数。 决策树算法决策树,类似于流程图,内部节点表示一个变量(或特性)的数据集,树枝表示决策规则,每一片叶子节点表示具体的结果决定。第一个节点的决策树图是根节点。我们可以分拆数据基于属性值对应于独立的特点。 的递归分区方法是树的划分成不同的元素。决策由这个决策树的综合辅助结构,它看起来像一个流程图。它提供了一个图解模型,准确反映个人原因和如何选择。因为这个性质的流程图,决策树很容易理解和理解。 决策树算法:它如何运作? 每个决策树算法的基本原则如下:
决策树回归使用决策树算法和预测未来事件产生深刻的连续的输出数据类型、决策树回归算法分析对象的属性和火车这台机器学习模型作为一个树。因为一套预定的离散数字不完全定义,输出或结果不离散。 这个模型说明了一个离散输出的板球比赛预测,预测一个特定的团队是否会赢得或失去比赛。 销售预测机器学习模型,预测公司的利润范围会增加整个财政年度根据公司的初步数据说明了连续输出。 决策树回归算法是利用在这个实例中预测连续值。 谈论sklearn决策树之后,让我们来看看他们是如何一步一步实现。 代码 输出: 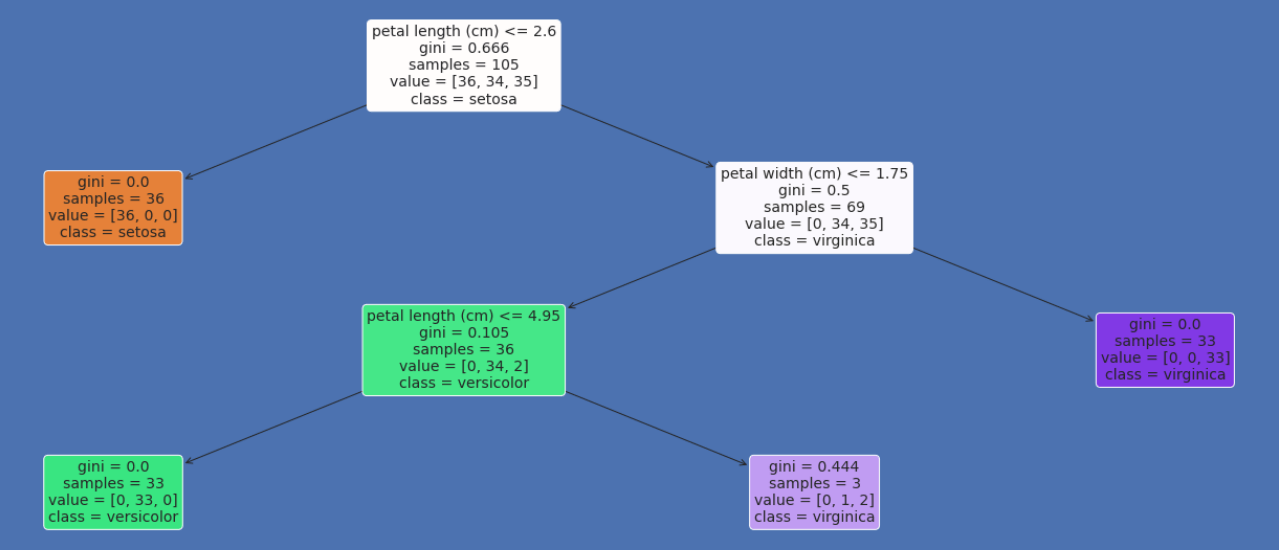 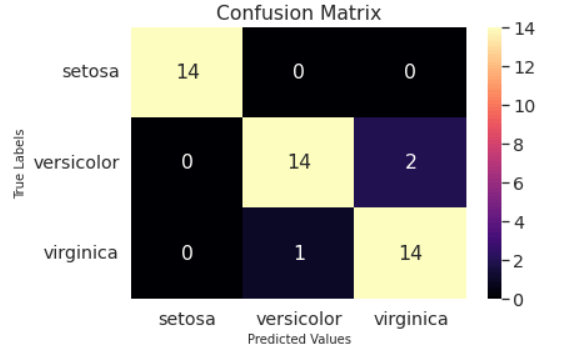
下一个话题
Python书籍对数据结构和算法
|
 加入我们的Youtube频道视频:现在加入
加入我们的Youtube频道视频:现在加入
反馈
- 把你的反馈(电子邮件保护)
帮助别人,请分享








