|
|

二叉决策树二叉决策树是一个决策图,它遵循从根节点开始并以导节点结束的顺序。这里的叶节点表示我们希望通过决策实现的输出。它直接受到二叉树的启发。由于二叉树中每个节点最多可以有两个节点,因此,在每一步中,我们都有一个或两个步骤,我们将从中选择一个。 它是一种决策算法,用于机器学习当我们有很多数据,我们想要得到每一步处理后的结果。 如果没有适当的约束,Decision Tree可能会扩展到每个节点上只有一个样本(或非常少的数量)。由于这种情况,模型变得过拟合,失去了准确泛化的能力。这个问题可以通过使用一致的测试集、交叉验证和最大允许深度来避免。职业平衡是另一个需要考虑的关键因素。当一个职业占主导地位时,决策树会产生不准确的结果,因为它们会对不平衡的职业做出反应。其中一种重采样技术,或类权重选项,由scikit-learn实现,可用于缓解此问题。通过避免偏见,统治阶级可以受到相应的惩罚。 假设在一个数据集中,我们有n数据点,每个点都有米特性。那么决策树可能是这样的t是阈值值: 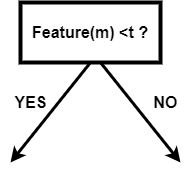 单分裂节点所以在二叉决策树中,每个节点的选择都应该使我们为该节点选择的特征能够以最好的方式分离数据。如果我们选择这样一个节点,它减少了步数,我们以更少的步数和复杂性得到目标。 在现实生活中,选择或找到最小化二叉决策树结构的特征是非常困难的。树的结构取决于我们选择的特征和阈值。 例如:我们有一个班的学生,所有的男孩都有黑色的头发,女孩都有绿色的头发。黑色表示不同长度的学生,红色表示不同长度的学生。如果我们的目标是得到黑色和绿色头发数据的组合,那么一个简单的二叉决策树可以是这样的: 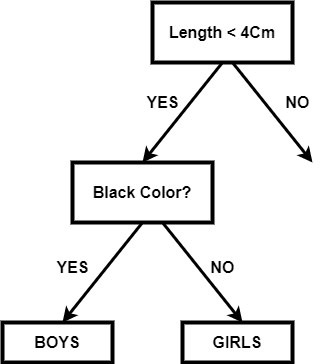 在上面的树中,我们根据头发的长度进行了划分,然后根据头发的颜色进行了划分。因为我们不需要根据头发的长度来分离,所以它被称为杂质。将杂质节点添加到树中,这会不必要地使结构变得更大、更复杂。如果杂质节点在目标节点以下,则没有问题。 所以我们可以得到上面例子的最优树: 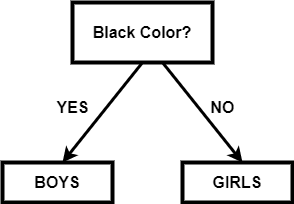 如果我们需要关于头发长度的数据,那么这个节点可以很容易地添加到叶节点的下面。 注:所以,每个节点的选择可以用下式表示:在上面的方程中,我们有两个值,其中我表示要拆分的数据集的索引。在根节点,我们将有一个完整的数据集,这样我将为零,在连续的步骤中,数据集将被缩减。tk表示分割数据集的阈值。所以我们在选择阈值的时候要非常小心因为阈值决定了树的结构。如果我们的阈值不好,那么我们可以得到一个很长的树来达到目标。 我们可以测量总杂质,我们的目标是减少总杂质,以尽快达到理想的节点。 总杂质量可由下式求得: 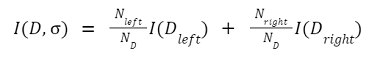 在这里D表示我们正在处理的完整数据集。D左和D正确的表示根据阈值分割后生成的左右节点数据集。 我表示节点的总杂质测度。
下一个话题
c++中的布尔值到字符串
|
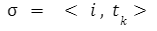
 视频加入我们的Youtube频道:现在加入
视频加入我们的Youtube频道:现在加入
反馈
- 将你的意见发送至(电子邮件保护)
帮助别人,请分享








