|
|

卷积神经网络模型的训练在上一个主题中,我们实现了CNN模型。现在,我们的下一个任务是训练它。为了训练我们的CNN模型,我们将涉及CUDA张量类型,它将实现与CPU张量相同的功能,但它们用于计算。 训练我们的CNN模型有以下步骤: 步骤1: 在训练部分的第一步中,我们将使用的帮助指定设备torch.device ().我们将检查CUDA;如果CUDA可用,那么我们使用CUDA,否则我们将使用CPU。 步骤2: 在下一步中,我们将把我们的模型分配给我们的设备: 步骤3: 现在,我们来定义损失函数。损失函数的定义方式与我们在之前使用深度神经网络的模型中定义的方式相同。 之后,我们将使用熟悉的优化器,即Adam as 步骤4: 在下一步中,我们将指定epoch的数量。我们初始化了epoch的个数,并用图分析了每个epoch的损失。我们将初始化两个列表,即loss_history和correct history。 步骤5: 我们将从迭代每个epoch开始,对于每个epoch,我们必须迭代训练加载器提供给我们的每一个训练批。在训练加载器中,每批训练包含100张图像和100个火车标签,分别为: 步骤6: 我们处理的是卷积神经网络输入首先被传递。我们将在四维空间中传递图像,因此不需要将它们压平。 正如我们已经将模型分配给我们的设备一样,我们也将输入和标签分配给我们的设备。 现在,在这些输入的帮助下,我们得到输出如下: 第七步: 在下一步中,我们将以与之前在图像识别中相同的方式执行优化算法。 第八步: 为了跟踪每个纪元的损失,我们将初始化一个变量loss,即running_loss。对于每批计算的每一个损失,我们必须把每批的损失都加起来,然后计算每个纪元的最终损失。 现在,我们将把整个时期的累计损失附加到我们的损失列表中。为此,我们在循环语句后使用else语句。一旦for循环结束,else语句就会被调用。在这个else语句中,我们将打印整个数据集在该特定纪元计算的累积损失。 步骤11: 在下一步,我们将找到我们的网络的准确性。我们将初始化正确的变量并将值赋为0。我们将比较模型对每个训练图像的预测与图像的实际标签,以显示在一个epoch内有多少是正确的。 对于每张图像,我们将取最大得分值。在这种情况下,返回一个元组。它返回的第一个值是实际的最高值——最大分数,这是由模型为这批图像中的每一张图像所做的。因此,我们对第一个元组值不感兴趣,第二个元组值将对应于由模型做出的最高预测,我们称之为preds。它将返回该图像的最大值的索引 步骤12: 每个图像输出将是一个索引范围从0到9的值的集合,这样MNIST数据集包含从0到9的类。由此可见,最大值发生的预测与模型的预测相对应。我们将把模型做出的所有预测与图像的实际标签进行比较,看看有多少预测是正确的。 这将为每一批图像提供正确预测的数量。我们将用与历元损失相同的方式定义历元精度,并将历元损失和精度打印为 这将给出预期的结果: 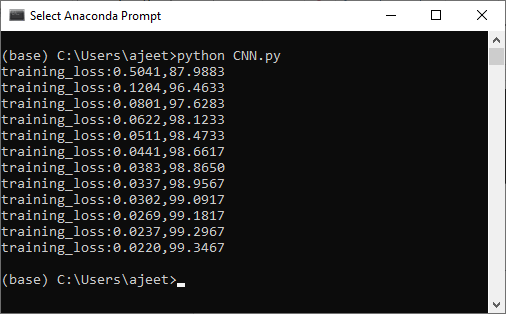 步骤13: 现在,我们将把整个epoch的准确度附加到correct_history列表中,为了更好地可视化,我们将把epoch损失和准确度绘制为 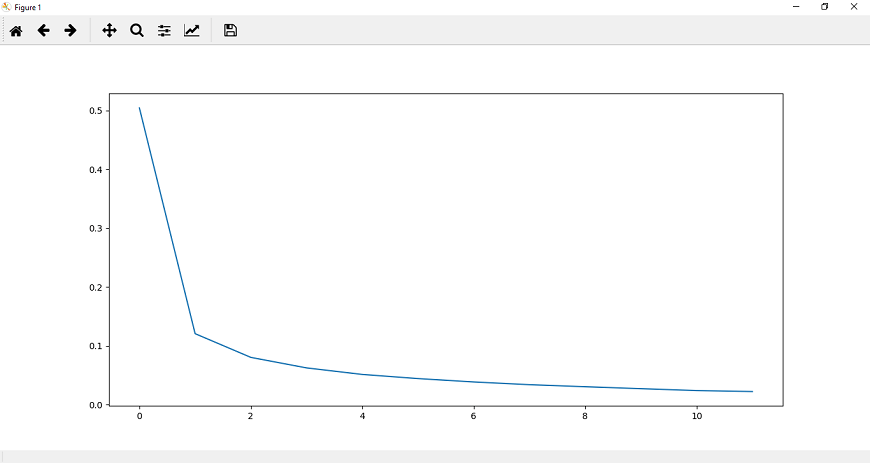 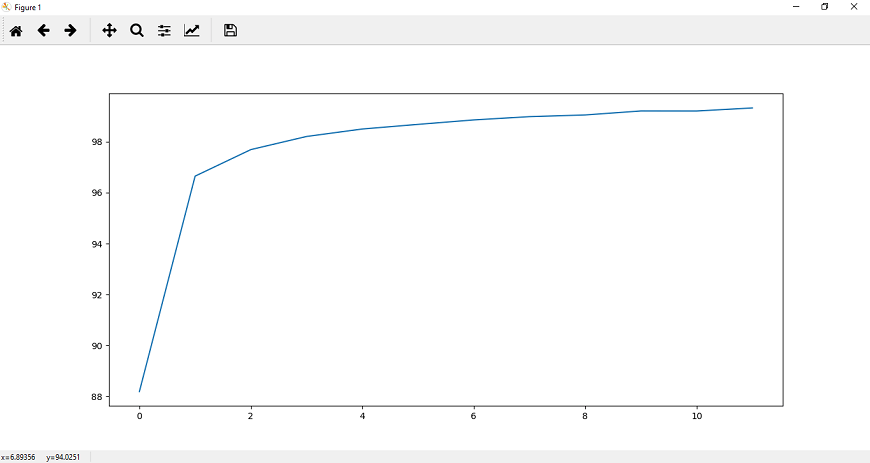
完整的代码:
下一个话题
CNN的验证
|
 观看视频请加入我们的Youtube频道:现在加入
观看视频请加入我们的Youtube频道:现在加入
反馈
- 将你的反馈发送至(电子邮件保护)
帮助他人,请分享








